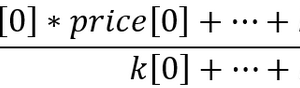交易者经常需要分析大量数据。 这些通常包括数字、报价、指标值和交易报告。 由于这些数字所依赖的参数和条件数量众多,我们应将它们分开考虑,并从不同角度观察整个过程。 整体信息量形成了一种虚拟超立方体,其中每个参数定义其自身的维度,该维度与其余维度相互垂直。
可以使用流行的 OLAP(
在线分析处理)技术处理和分析这种超立方体。
方法名称中的“在线 (online)”一词不是指互联网,而是指结果的及时性。 操作原理意味着超立方体单元的初步计算,之后您能够以直观的形式快速提取和查看立方体的任何横截面。 可将之与 MetaTrader
中的优化过程进行比较:测试器首先计算交易变量(可能需要相当长的时间,即使并未提示),然后输出报告,其结果与输入参数相关联。 从 MetaTrader 5 Build 1860 开始,平台支持通过切换各种优化条件来查看优化结果的动态变化。 这与 OLAP
的理念十分接近。 但是对于完整的分析,我们需要选择超立方体的许多其他切面的能力。
我们会尝试在 MetaTrader 中应用 OLAP 方法,并利用 MQL 工具实现多维分析。 在继续实现之前,我们需要确定所要分析的数据。 这些可能包括交易报告、优化结果或指标值。
此阶段的选择并不十分重要,因为我们的目标是开发适用于任何数据的通用面向对象引擎。 但我们需要将引擎应用于特定结果。 最热门的任务之一是分析交易报告。 我们将考查这项任务。
在交易报告中,按品种、周内星期值、买卖操作来细分利润也许会有用。 另一种选择是比较不同交易机器人的性能结果(即,按魔幻数字逐一划分)。 下一个合乎逻辑的问题在于,是否可以组合各种维度:品种按星期值与智能交易系统关联,或添加其他一些分组。 所有这些都可以利用 OLAP 完成。
体系结构
根据面向对象的方法,大型任务应该分解为简单的逻辑相关部分,而每个部分根据传入数据,内部状态和一些规则集合执行自己的角色。
我们将使用的第一个类是包含源数据的记录 — ‘Record’。 这样的记录可以存储一次交易操作或一个优化过程相关的数据,等等。
‘Record’ 是具有任意数量字段的向量。 由于这是一个抽象的实体,每个字段的含义并不重要。 对于每个特定的应用程序,我们将创建一个派生类,它“知道”字段的用途,并相应地处理它们。
需要另一个类 ‘DataAdapter’ 从一些抽象来源读取记录(例如交易账户历史,CSV 文件,HTML 报告,或使用 WebRequest 从网络上获得的数据)。 在此阶段它只执行一个功能:它逐个遍历记录,并提供对它们的访问。
稍后,我们能够为每个实际应用程序创建派生类。 这些类将从相关来源填充记录数组。
所有记录都可能以某种方式显示在超立方体单元中。 在此阶段我们无需知道如何做到这一点,但这是本项目的思路:从多维数据集合单元中的记录字段派发输入值,并使用所选的聚合函数计算广义统计数据。
基本多维数据集合级别仅提供主要属性,例如维度数、名称和每个维度的大小。 此数据在 MetaCube 类中提供。
派生类随后将相关统计信息填入这些单元。 特定聚合器的最常见示例包括所有值的总和,或所有记录相同字段的平均值。 不过会有更多不同类型的聚合器。
若要启用单元中数值的聚合,每个记录必须接收一组索引,这些索引将其映射到多维数据集合的某个唯一单元。 此任务将由特殊的 “Selector” 类执行。 Selector 对应于超立方体的一侧(轴,坐标)。
抽象 Selector 基类提供了一个可编程接口,用于定义一组有效值,并将每个条目映射到其中一个值。 例如,如果目的是按星期值切分记录,则派生的 Selector 类应返回星期值的编号,从 0 到 6。 特定 Selector
的允许值数量定义此多维数据集维度的大小。 这对于星期值来说是显而易见的,即 7。
此外,有时对于滤除一些记录(从分析中排除它们)很有用。 因此,我们需要一个 Filter 类。 它与 Selector 类似,但它对允许值设置了额外的限制。 例如,我们可以基于星期值的选择器创建一个过滤器。 在该过滤器中,可以指定需要从计算中排除或包含在其中的星期值。
一旦创建了多维数据集合(即,所有单元的聚合函数已计算完毕),结果就能够可视化并分析。 为此目的,我们保留特殊的 “Display” 类。
若要将所有上述所有类组合成一个整体,我们应创建一种控制中心,即 Analyst 类。
这在 UML 表示法中如下所示(这可视为一个行动计划,可在任何开发阶段进行检查)。

MetaTrader 中的在线分析处理
此处省略了一些类。 然而,它反映了超立方体构造的常规基础,并且它展示了可用于计算超立方体单元的聚合函数。
基类实现
现在我们将继续实现上述类。 我们从 Record 类开始。
class Record { private: double data[]; public: Record(const int length) { ArrayResize(data, length); ArrayInitialize(data, 0); } void set(const int index, double value) { data[index] = value; } double get(const int index) const { return data[index]; } };
它只简单地将任意值存储在 ‘data’ 数组(向量)中。 向量长度在构造函数中设置。
利用 DataAdapter 读取不同来源的记录。
class DataAdapter { public: virtual Record *getNext() = 0; virtual int reservedSize() = 0; };
必须在循环中调用 getNext 方法,直到它返回 NULL(这意味着没有更多记录)。 所有收到的记录都应保存在某处(此任务稍后将会讨论)。 reservedSize 方法支持优化的内存分配(如果提前知道源中的记录数量)。
每个超立方体维度基于一个或多个记录字段计算。 出于便利,将每个字段用一个枚举元素标记。 例如,为了分析账户交易历史,可以使用以下枚举。
// MT4 和 MT5 对冲账户 enum TRADE_RECORD_FIELDS { FIELD_NONE, // 无 FIELD_NUMBER, // 序列号 FIELD_TICKET, // 票据 FIELD_SYMBOL, // 品种 FIELD_TYPE, // 类型 (OP_BUY/OP_SELL) FIELD_DATETIME1, // 开单时间 FIELD_DATETIME2, // 平单时间 FIELD_DURATION, // 持续时间 FIELD_MAGIC, // 魔幻数字 FIELD_LOT, // 手数 FIELD_PROFIT_AMOUNT, // 盈利额 FIELD_PROFIT_PERCENT,// 盈利百分比 FIELD_PROFIT_POINT, // 赢利点数 FIELD_COMMISSION, // 佣金 FIELD_SWAP, // 隔夜利息 FIELD_CUSTOM1, // 自定义 1 FIELD_CUSTOM2 // 自定义 2 };
最后两个字段可用于计算非标准变量。
建议以下枚举用于 MetaTrader 优化结果的分析。
enum OPTIMIZATION_REPORT_FIELDS { OPTIMIZATION_PASS, OPTIMIZATION_PROFIT, OPTIMIZATION_TRADE_COUNT, OPTIMIZATION_PROFIT_FACTOR, OPTIMIZATION_EXPECTED_PAYOFF, OPTIMIZATION_DRAWDOWN_AMOUNT, OPTIMIZATION_DRAWDOWN_PERCENT, OPTIMIZATION_PARAMETER_1, OPTIMIZATION_PARAMETER_2, //... };
应为每个实际应用案例准备独立的枚举。 然后它可以作为 Selector 模板类的参数。
template<typename E> class Selector { protected: E selector; string _typename; public: Selector(const E field): selector(field) { _typename = typename(this); } // 返回单元索引以存储记录中的值 virtual bool select(const Record *r, int &index) const = 0; virtual int getRange() const = 0; virtual float getMin() const = 0; virtual float getMax() const = 0; virtual E getField() const { return selector; } virtual string getLabel(const int index) const = 0; virtual string getTitle() const { return _typename + "(" + EnumToString(selector) + ")"; } };
selector 字段只存储一个值,即枚举的一个元素。 例如,如果使用了 TRADE_RECORD_FIELDS,则可以按如下方式创建买/卖操作的选择器:
new Selector<TRADE_RECORD_FIELDS>(FIELD_TYPE);
_typename 字段作为辅助。 它将在所有派生类中被重写,以便识别选择器,这在可视化结果时很有用。 该字段在虚拟 getTitle 方法当中会用到。
操作的主要部分由 “select” 方法中的类执行。 在此,每个输入记录被映射为沿坐标轴的特定索引值,该坐标轴由当前选择器形成。 索引必须在 getMin 和 getMax 方法返回数值之间的范围内,而索引的总数等于 getRange 返回的数字。
如果出于某种原因,记录无法在段落定义区域中正确映射,’select’ 方法返回 false。 如果映射已正确执行,则返回 true。
getLabel 方法返回一段用户友好的特定索引描述。 例如,对于买/卖操作,索引 0 必须生成 “buy”,而索引 1 必须生成 “sell”。
为交易历史实现特殊的选择器和数据适配器类
由于我们即将分析交易历史,因此我们将根据 TRADE_RECORD_FIELDS 枚举引入一组中间选择器。
class TradeSelector: public Selector<TRADE_RECORD_FIELDS> { public: TradeSelector(const TRADE_RECORD_FIELDS field): Selector(field) { _typename = typename(this); } virtual bool select(const Record *r, int &index) const { index = 0; return true; } virtual int getRange() const { return 1; // 默认情况下,这是一个标量,返回数值 1 } virtual double getMin() const { return 0; } virtual double getMax() const { return (double)(getRange() - 1); } virtual string getLabel(const int index) const { return EnumToString(selector) + "[" + (string)index + "]"; } };
默认情况下,它将所有记录映射到同一个单元。 例如,使用此选择器,您可以获取总利润数据。
现在,基于此选择器,我们可以轻松判定选择器的特定衍生类型。 这也用于按操作类型(买/卖)对记录进行分组。
class TypeSelector: public TradeSelector { public: TypeSelector(): TradeSelector(FIELD_TYPE) { _typename = typename(this); } virtual bool select(const Record *r, int &index) const { ... } virtual int getRange() const { return 2; // OP_BUY, OP_SELL } virtual double getMin() const { return OP_BUY; } virtual double getMax() const { return OP_SELL; } virtual string getLabel(const int index) const { const static string types[2] = {"buy", "sell"}; return types[index]; } };
我们在构造函数中用 FIELD_TYPE 元素定义了类。 getRange 方法返回 2,因为这里我们只有 2 种可能的类型:OP_BUY 或 OP_SELL。 getMin 和 getMax 方法返回相应的常量。 ‘select’ 方法应该包含什么?
首先,我们需要决定在每条记录中将存储哪些信息。 这可以利用 TradeRecord 类来完成,该类源自 Record,并适用于交易历史。
class TradeRecord: public Record { private: static int counter; protected: void fillByOrder() { set(FIELD_NUMBER, counter++); set(FIELD_TICKET, OrderTicket()); set(FIELD_TYPE, OrderType()); set(FIELD_DATETIME1, OrderOpenTime()); set(FIELD_DATETIME2, OrderCloseTime()); set(FIELD_DURATION, OrderCloseTime() - OrderOpenTime()); set(FIELD_MAGIC, OrderMagicNumber()); set(FIELD_LOT, (float)OrderLots()); set(FIELD_PROFIT_AMOUNT, (float)OrderProfit()); set(FIELD_PROFIT_POINT, (float)((OrderType() == OP_BUY ? +1 : -1) * (OrderClosePrice() - OrderOpenPrice()) / SymbolInfoDouble(OrderSymbol(), SYMBOL_POINT))); set(FIELD_COMMISSION, (float)OrderCommission()); set(FIELD_SWAP, (float)OrderSwap()); } public: TradeRecord(): Record(TRADE_RECORD_FIELDS_NUMBER) { fillByOrder(); } };
辅助的 fillByOrder 方法演示了如何根据当前订单填充大多数记录字段。 当然,必须在代码中的其他位置预先选择订单。 在此我们使用 MetaTrader 4 交易函数的表示法。 MetaTrader 5 的支持将通过包含 MT4Orders
函数库来实现(其中一个版本附在下面,应始终检查并下载当前版本)。 因此,我们可以创建跨平台代码。
TRADE_RECORD_FIELDS_NUMBER 字段的数量可以用宏定义硬编码,也可以根据 TRADE_RECORD_FIELDS 枚举动态计算。 第二种方法在附带代码中实现,其中使用了特殊模板化的 EnumToArray 函数。
正如从 fillByOrder 方法里看到的,FIELD_TYPE 字段由 OrderType 中的操作类型填充。 现在我们可以回到 TypeSelector 类并实现它的 ‘select’ 方法。
virtual bool select(const Record *r, int &index) const { index = (int)r.get(selector); return index >= getMin() && index <= getMax(); }
此处我们从输入记录(r)中读取字段值(selector)并将其值(可以是 OP_BUY 或 OP_SELL)分配给索引输出参数。 计算仅包括入场订单,因此对所有其他类型返回 false。 稍后我们将考虑其他选择器类型。
现在是时候为交易历史开发数据适配器了。 根据账户的真实交易历史,生成 TradeRecord 记录的类。
class HistoryDataAdapter: public DataAdapter { private: int size; int cursor; protected: void reset() { cursor = 0; size = OrdersHistoryTotal(); } public: HistoryDataAdapter() { reset(); } virtual int reservedSize() { return size; } virtual Record *getNext() { if(cursor < size) { while(OrderSelect(cursor++, SELECT_BY_POS, MODE_HISTORY)) { if(OrderType() < 2) { return new TradeRecord(); } } return NULL; } return NULL; } };
适配器按顺序传递历史记录中可用的所有订单,并为每笔入场订单创建 TradeRecord 实例。 此处呈现的代码只是简化形式。 在实际运用过程中,我们可能需要创建不属于 TradeRecord 类的对象,而是创建派生类的对象:我们为 TRADE_RECORD_FIELDS 枚举保留了两个自定义字段。
所以,HistoryDataAdapter 是模板类,而 template 参数是所生成记录对象的实际类。 Record 类必须包含一个用于填充自定义字段的空虚拟方法:
virtual void fillCustomFields() {/* does nothing */};
您可以自行分析完整的实现方法:在核心中使用 CustomTradeRecord 类。 在 fillCustomFields 中,此类(它是 TradeRecord 的子代)计算每笔仓位的 MFE(最大有利偏移)和 MAE(最大不利偏移),并将这些值记录到 FIELD_CUSTOM1 和
FIELD_CUSTOM2 字段中。
实现聚合器和控制类
我们需要一个地方来创建适配器,并调用其 getNext 方法。 现在我们将处理“控制中心”,即 Analyst 类。 除了启动适配器之外,该类还必须将接收到的记录存储在内部数组中。
template<typename E> class Analyst { private: DataAdapter *adapter; Record *data[]; public: Analyst(DataAdapter &a): adapter(&a) { ArrayResize(data, adapter.reservedSize()); } ~Analyst() { int n = ArraySize(data); for(int i = 0; i < n; i++) { if(CheckPointer(data[i]) == POINTER_DYNAMIC) delete data[i]; } } void acquireData() { Record *record; int i = 0; while((record = adapter.getNext()) != NULL) { data[i++] = record; } ArrayResize(data, i); } };
该类不会创建适配器,但它接收一个准备好的适配器作为构造函数参数。 这是一个众所周知的设计原则 — 依赖注入。
它允许从特定的 DataAdapter 实现中隔离 Analyst。 换言之,我们可以轻松替换各种适配器变体,而无需在 Analyst 类中进行修改。
Analyst 类现在能够填充内部记录数组,但它仍然不知道如何执行主函数,即如何聚合数据。 此任务将由聚合器实现。
聚合器是可以计算所选记录字段的预定义变量(统计数据)的类。 聚合器的基类是 MetaCube,它是基于多维数组的存储。
class MetaCube { protected: int dimensions[]; int offsets[]; double totals[]; string _typename; public: int getDimension() const { return ArraySize(dimensions); } int getDimensionRange(const int n) const { return dimensions[n]; } int getCubeSize() const { return ArraySize(totals); } virtual double getValue(const int &indices[]) const = 0; };
‘dimensions’ 数组描述了超立方体结构。 它的大小等于所用选择器的数量,即维度。 ‘dimensions’ 数组的每个元素都包含此维度中的多维数据集合大小,该大小取决于相应选择器的数值范围。
例如,为了按星期值查看利润,我们需要创建一个选择器,根据订单(仓位)的开单或平单时间,将星期编号从 0 到 6 作为索引返回。 由于这是唯一的选择器,’dimensions’ 数组将包含 1 个元素,其值将为 7。 如果我们添加另一个选择器,例如前面描述的
TypeSelector,按星期值和操作类型查看利润,’dimensions’ 数组将包含 2 个元素,其值为 7 和 2。 这也意味着超立方体将包含 14 个带统计数据的单元。
含有所有数值的数组(在我们的示例中为 14)包含在 “totals” 中。 由于超立方体是多维的,因此也许看起来数组只是被声明为只有一个维度。 这是因为我们事先并不知道用户需要添加的超立方体维度。 此外,MQL 不支持多维数组,其中所有绝对维度都将动态分布。
所以,使用通常的“平面”数组(矢量)。 在此数组中使用特殊索引在多个维度上存储单元。 接下来,我们研究每个维度的偏移计算。
基类不分配也不初始化数组,这些是由派生类执行的。
由于预期所有聚合器都具有许多共同特征,因此我们将它们打包在一个中间类中。
template<typename E> class Aggregator: public MetaCube { protected: const E field;
每个聚合器处理特定的记录字段。 该字段在类中的 “field” 变量中指定,该变量在构造函数中填充(参见下文)。 例如,这可以是利润(FIELD_PROFIT_AMOUNT)。
const int selectorCount; const Selector<E> *selectors[];
计算在多维空间中执行,该空间由任意数量的选择器(selectorCount)形成。 我们之前已经研究了按星期值和按操作类型划分的利润计算,这需要两个选择器。 它们存储在 “selectors” 引用数组中。 选择器对象作为参数传递给构造函数。
public: Aggregator(const E f, const Selector<E> *&s[]): field(f), selectorCount(ArraySize(s)) { ArrayResize(selectors, selectorCount); for(int i = 0; i < selectorCount; i++) { selectors[i] = s[i]; } _typename = typename(this); }
您还记得,用于存储计算值的 ‘totals’ 数组是一维的。 以下函数用于将多维选择器空间的索引转换为一维数组中的偏移量。
int mixIndex(const int &k[]) const { int result = 0; for(int i = 0; i < selectorCount; i++) { result += k[i] * offsets[i]; } return result; }
它接受一个数组和索引作为输入,并返回该元素的序号。 在此使用 ‘offsets’ 数组 — 此时数组必须已经填充。 它的初始化是关键点之一,它在 setSelectorBounds 方法中执行。
virtual void setSelectorBounds() { ArrayResize(dimensions, selectorCount); int total = 1; for(int i = 0; i < selectorCount; i++) { dimensions[i] = selectors[i].getRange(); total *= dimensions[i]; } ArrayResize(totals, total); ArrayInitialize(totals, 0); ArrayResize(offsets, selectorCount); offsets[0] = 1; for(int i = 1; i < selectorCount; i++) { offsets[i] = dimensions[i - 1] * offsets[i - 1]; // 1, X, Y*X } }
它的目的是获得所有选择器的范围,并将它们顺序相乘:由此,我们可以判定在每个超立方体维度中将坐标增加 1 时“跳过”的元素数量。
聚合变量的计算在 calculate 方法中执行。
// 构建一个维数等于选择器数量的数组 virtual void calculate(const Record *&data[]) { int k[]; ArrayResize(k, selectorCount); int n = ArraySize(data); for(int i = 0; i < n; i++) { int j = 0; for(j = 0; j < selectorCount; j++) { int d; if(!selectors[j].select(data[i], d)) // 记录是否满足选择器? { break; // 若非,则跳过它 } k[j] = d; } if(j == selectorCount) { update(mixIndex(k), data[i].get(field)); } } }
针对记录数组调用该方法。 在循环中将每个记录依次传递给每个选择器。 如果它成功映射到所有选择器中的有效索引中(每个选择器都有自己的索引),那么完整的索引集合将保存在局域 k 数组中。 如果所有选择器都已确定索引,则调用 “update” 方法。
以下是方法的输入:’totals’ 数组中的偏移量(使用前面提到的 mixIndex 计算偏移量),和当前记录中指定的 ‘field’(在聚合器中设置)的值。 在利润分布分析示例中,’field’ 变量将等于
FIELD_PROFIT_AMOUNT,而此字段的值将调用 OrderProfit() 提供。
virtual void update(const int index, const float value) = 0;
在这个类中 update 方法是抽象的,必须在其继承者中重新定义。
聚合器还必须提供至少一种访问计算结果的方法。 其中最简单的一个是根据整个索引集合接收特定单元的数值。
double getValue(const int &indices[]) const { return totals[mixIndex(indices)]; } };
基类 Aggregator 执行几乎所有粗略的工作。 现在我们可以轻松实现许多特定的聚合器。
但首先,我们回到 Analyst 类:我们需要向它添加对聚合器的引用,聚合器也将作为参数传递给构造函数。
template<typename E> class Analyst { private: DataAdapter *adapter; Record *data[]; Aggregator<E> *aggregator; public: Analyst(DataAdapter &a, Aggregator<E> &g): adapter(&a), aggregator(&g) { ArrayResize(data, adapter.reservedSize()); }
在 acquireData 方法中,我们将额外调用聚合器的 setSelectorBounds 方法来配置超立方体维度。
void acquireData() { Record *record; int i = 0; while((record = adapter.getNext()) != NULL) { data[i++] = record; } ArrayResize(data, i); aggregator.setSelectorBounds(i); }
主要任务,即超立方体的所有数值的计算,将在聚合器中实现(我们之前已研究过 ‘calculate’ 方法; 记录数组于此传递给它)。
void build()
{
aggregator.calculate(data);
}
这不是关于 Analyst 类的全部内容。 早前,我们计划将其形式化为特殊的 Display 接口来显示结果。 接口以类似的方式连接到 Analyst(通过给构造函数传递引用):
template<typename E> class Analyst { private: ... Display *output; public: Analyst(DataAdapter &a, Aggregator<E> &g, Display &d): adapter(&a), aggregator(&g), output(&d) { ... } void display() { output.display(aggregator); } };
“Display” 的内容很简单:
class Display { public: virtual void display(MetaCube *metaData) = 0; };
它包含一个抽象虚拟方法,超立方体作为数据源输入到该方法中。 为简洁起见,这里省略了影响数值打印顺序的一些参数。 可视化细节和必要的附加设置将出现在派生类中。
若要测试分析类,我们需要至少有一个 ‘Display’ 接口的实现。 我们创建它向智能系统日志输出消息。 它将被称为 LogDisplay。 接口将循环遍历超立方体的所有坐标,并将聚合值与相应的坐标一起打印,大致如下:
class LogDisplay: public Display { public: virtual void display(MetaCube *metaData) override { int n = metaData.getDimension(); int indices[], cursors[]; ArrayResize(indices, n); ArrayResize(cursors, n); ArrayInitialize(cursors, 0); for(int i = 0; i < n; i++) { indices[i] = metaData.getDimensionRange(i); } bool looping = false; int count = 0; do { ArrayPrint(cursors); Print(metaData.getValue(cursors)); for(int i = 0; i < n; i++) { if(cursors[i] < indices[i] - 1) { looping = true; cursors[i]++; break; } else { cursors[i] = 0; } looping = false; } } while(looping && !IsStopped()); } };
我说’粗略’是因为若要实现更方便的日志格式,LogDisplay 会更复杂一些。 该类的完整版本在附加的源代码中提供。
当然,这不如图表那么高效,但是二维或三维图像的创建是另一个单独的主题,我们在此不予考虑(尽管您可以使用不同的技术,例如对象,画布和外部图形库,包括基于 web 技术)。
因此,我们有 Aggregator 基类。 在此基础上,我们可以轻松地获取几个派生类,并在 update 方法中用到特殊的聚合变量计算。 特别是,以下简单代码可用于计算从某个选择器所有记录中提取的数值总和:
template<typename E> class SumAggregator: public Aggregator<E> { public: SumAggregator(const E f, const Selector<E> *&s[]): Aggregator(f, s) { _typename = typename(this); } virtual void update(const int index, const float value) override { totals[index] += value; } };
计算平均值只是略复杂一点:
template<typename E> class AverageAggregator: public Aggregator<E> { protected: int counters[]; public: AverageAggregator(const E f, const Selector<E> *&s[]): Aggregator(f, s) { _typename = typename(this); } virtual void setSelectorBounds() override { Aggregator<E>::setSelectorBounds(); ArrayResize(counters, ArraySize(totals)); ArrayInitialize(counters, 0); } virtual void update(const int index, const float value) override { totals[index] = (totals[index] * counters[index] + value) / (counters[index] + 1); counters[index]++; } };
已研究了所涉及的所有类,我们来概括它们的交互算法:
- 创建 HistoryDataAdapter 对象;
- 创建若干个特定的选择器(每个选择器至少与一个字段绑定,例如交易操作类型,等等),并将它们保存到数组中;
- 创建特定的聚合器对象,例如 SumAggregator。 将选择器数组和字段指示传递给它,根据该指示执行聚合;
- 创建 LogDisplay 对象;
- 使用适配器对象创建 Analyst 对象,聚合器和显示;
- 按顺序调用:
analyst.acquireData();
analyst.build();
analyst.display();
- 不要忘记最后删除对象。
特例:动态选择器
我们的程序几乎准备就绪。 之前我们为了简化描述而省略了它的一部分。 现在是时候理清它了。
所有上述选择器具有恒定的数值范围。 例如,一周总有 7 天,而入场订单要么是买入亦或卖出。 然而,也许不会事先知道该范围,而这种情况经常发生。
我们也许需要一个反映操作品种或 EA 魔幻数字的超立方体。 对于此任务的解决方案,我们首先需要在一些内部数组中收集所有的金融产品或魔幻数字,然后我们将用到的数组大小与选择器范围相关。
我们创建用于管理这些内部数组的 “Vocabulary” 类。 我们将结合 SymbolSelector 类来分析它的用法。
我们的 vocabulary 实现非常简单(您可以用任意首选来替换它)。
template<typename T> class Vocabulary { protected: T index[];
保留的 ‘index’ 数组用于存储唯一值。
public: int get(const T &text) const { int n = ArraySize(index); for(int i = 0; i < n; i++) { if(index[i] == text) return i; } return -(n + 1); }
‘get’ 方法用于检查数组中是否已存在某些值。 如果存在这样的数值,则该方法返回找到的索引。 如果数组中不存在该值,则该方法返回数组大小加 1,且带负值。 这样可以稍微优化下次方法向数组添加新值。
int add(const T text) { int n = get(text); if(n < 0) { n = -n; ArrayResize(index, n); index[n - 1] = text; return n - 1; } return n; }
此外,我们需要提供接收数组大小,以及按索引取存储值的方法。
int size() const { return ArraySize(index); } T operator[](const int slot) const { return index[slot]; } };
在我们的例子中,在订单(仓位)的上下关联中分析操作品种,因此我们将词汇表嵌入到 TradeRecord 类中。
class TradeRecord: public Record { private: ... static Vocabulary<string> symbols; protected: void fillByOrder(const double balance) { ... set(FIELD_SYMBOL, symbols.add(OrderSymbol())); // 保存品种作为词汇表的索引 } public: static int getSymbolCount() { return symbols.size(); } static string getSymbol(const int index) { return symbols[index]; } static int getSymbolIndex(const string s) { return symbols.get(s); }
词汇表声明为静态变量,因为它是由整个交易历史共享的。
现在我们可以实现 SymbolSelector。
class SymbolSelector: public TradeSelector { public: SymbolSelector(): TradeSelector(FIELD_SYMBOL) { _typename = typename(this); } virtual bool select(const Record *r, int &index) const override { index = (int)r.get(selector); return (index >= 0); } virtual int getRange() const override { return TradeRecord::getSymbolCount(); } virtual string getLabel(const int index) const override { return TradeRecord::getSymbol(index); } };
魔幻数字选择器以类似的方式实现。
所提供选择器的一般列表包括以下内容(括号中指明必须绑定的外部字段; 如果省略,则表示已在选择器类内部提供了对特定字段的绑定):
- TradeSelector (任何字段) — 标量,一个数值(“real” 聚合器的所有记录的摘要,或 IdentityAggregator 的某个记录的字段值(见下文));
- TypeSelector — 取决于OrderType() 的买入或卖出;
- WeekDaySelector (datetime 类型字段) — 星期值,例如,在 OrderOpenTime() 或 OrderCloseTime();
- DayHourSelector (datetime 类型字段) — 日内的小时值;
- HourMinuteSelector (datetime 类型字段) — 小时内的分钟;
- SymbolSelector — 操作品种,OrderSymbol() 词汇表的唯一性索引;
- SerialNumberSelector — 记录的顺序号(订单);
- MagicSelector — 魔幻数字,OrderMagicNumber() 词汇表的唯一性索引;
- ProfitableSelector — true = 盈利, false = 亏损, 来自 OrderProfit() 字段;
- QuantizationSelector (double 类型字段) — 随机双精度类型数值的词汇表(例如,手数大小);
- DaysRangeSelector — 拥有两个 datetime 类型字段(OrderCloseTime() 和 OrderOpenTime())的自定义选择器示例,它基于 DateTimeSelector 类,即 datetime 类型字段的所有选择器的共同父级;
与核心中定义的其他选择器不同,此选择器在演示 EA 中实现(见下文)。
SerialNumberSelector 与其他选择器明显不同。 其范围等于记录总数。 这能够生成超立方体,其中记录按顺序记存在维度之一当中(通常在第一个维度中,X),而指定的字段被复制到另一个维度当中。 这些字段由选择器定义:专用选择器已经包含字段绑定;
如果您所需要的一个字段没有相应绑定的选择器,例如 ‘swap’,则可以使用通用 TradeSelector。 换句话说,SerialNumberSelector 在聚合超立方体隐喻中能够读取源记录数据。 这是通过使用伪聚合器
IdentityAggregator 完成的(见下文)。
可以使用以下聚合器:
- SumAggregator — 字段值的总和;
- AverageAggregator — 字段值的均值;
- MaxAggregator — 字段值的最大值;
- MinAggregator — 字段值的最小值;
- CountAggregator — 记录数量;
- ProfitFactorAggregator — 正数值总和与负数值总和的比值;
- IdentityAggregator (SerialNumberSelector 沿 X 轴) — 一种特殊的选择器类型,用于将字段值“透明地”复制到超立方体,而不进行聚合;
- ProgressiveTotalAggregator (SerialNumberSelector 沿 X 轴) — 该字段的累加和;
最后两个聚合器与其他聚合器不同。 选择 IdentityAggregator 时,超立方体大小始终等于 2。 记录使用 SerialNumberSelector 沿 X 轴反射,而沿第二轴(实际上是矢量/列)的每个计数对应于一个选择器,使用该选择器确定要从源记录中读取的字段。
因此,如果有三个额外的选择器(除了 SerialNumberSelector),沿 Y 轴将有三个计数。 然而,多维数据集合仍然有两个维度:X 轴和 Y 轴。 通常,多维数据集合是根据不同的原理生成的:每个选择器对应于其自身的尺寸,因此 3 个维度表示 3
个轴。
ProgressiveTotalAggregator 以特殊方式处理第一个维度。 顾名思义,聚合器可以计算累计总数,而这是沿 X 轴完成的。 例如,如果在 aggregator 参数中指定利润字段,则您将获得常规的余额曲线。 如果您沿 Y
轴(在第二个选择器中)绘制品种(SymbolSelector),则每个可用品种将有多个 [N] 余额曲线。 如果第二个选择器是 MagicSelector,则不同的 EA 交易将有单独的 [M] 余额曲线。 此外,参数均可组合:沿 Y 设置
SymbolSelector,并沿 Z 轴设置 MagicSelector(反之亦然):您将获得 [N*M] 余额曲线,每个曲线具有不同的魔幻和品种组合。
现在 OLAP 引擎已准备就绪。 我们省略了一些描述部分以便令文章更加简洁。 例如,本文并未提供在体系结构中提到的过滤器(Filter,FilterRange 类)的描述。 此外,这个超立方体不仅可以逐个呈现聚合值(方法 getValue(const
int&indices[])),而且还可以使用以下方法将它们作为向量返回:
virtual bool getVector(const int dimension, const int &consts[], PairArray *&result, const SORT_BY sortby = SORT_BY_NONE)
方法输出是特殊的 PairArray 类。 它在一个结构数组里存储 [数值;名称] 数据对。 例如,如果我们构建一个反映利润品种的多维数据集合,那么每个总和对应一个特定的品种 – 因此它的名称在数据对中靠数值旁边表示。 从方法原型中可以看出,它能够以不同的模式对
PairArray 进行排序:升序或降序,按数值或按标签:
enum SORT_BY // 仅适用于一维数值集合 { SORT_BY_NONE, // 无 SORT_BY_VALUE_ASCENDING, // 数值 (升序) SORT_BY_VALUE_DESCENDING, // 数值 (降序) SORT_BY_LABEL_ASCENDING, // 标签 (升序) SORT_BY_LABEL_DESCENDING // 标签 (降序) };
仅在一维超立方体上支持排序。 从理论上讲,它可以用于任意数量的维度,但这是一项十分常规的操作。 有兴趣的人可以实现这种排序。
附上完整的源代码。
OLAPDEMO 示例
现在我们来测试超立方体。 我们创建一个非交易的智能交易系统,它可以分析账户交易历史。 我们称之为 OLAPDEMO。 包含所有主要 OLAP 类的头文件。
#include <OLAPcube.mqh>
尽管超立方体可以处理任意数量的维度,但为了简单起见,我们现在将它们限制为三维。 这意味着用户可以同时使用多达 3 个选择器。 使用特殊枚举的元素定义所支持的选择器类型:
enum SELECTORS { SELECTOR_NONE, // 无 SELECTOR_TYPE, // 类型 SELECTOR_SYMBOL, // 品种 SELECTOR_SERIAL, // 序数 SELECTOR_MAGIC, // 魔幻数字 SELECTOR_PROFITABLE, // 可盈利 /* 自定义选择器 */ SELECTOR_DURATION, // 持续天数 /* 以下所有都需要一个字段作为参数 */ SELECTOR_WEEKDAY, // 星期值(datetime 字段) SELECTOR_DAYHOUR, // 日内小时(datetime 字段) SELECTOR_HOURMINUTE, // 小时内分钟(datetime 字段) SELECTOR_SCALAR, // 标量(字段) SELECTOR_QUANTS // 定量(字段) };
使用枚举来描述设置选择器的输入参数:
sinput string X = "————— X axis —————"; input SELECTORS SelectorX = SELECTOR_SYMBOL; input TRADE_RECORD_FIELDS FieldX = FIELD_NONE /* field does matter only for some selectors */; sinput string Y = "————— Y axis —————"; input SELECTORS SelectorY = SELECTOR_NONE; input TRADE_RECORD_FIELDS FieldY = FIELD_NONE; sinput string Z = "————— Z axis —————"; input SELECTORS SelectorZ = SELECTOR_NONE; input TRADE_RECORD_FIELDS FieldZ = FIELD_NONE;
每个选择器组包含一个用于设置可选记录字段的输入(某些选择器需要字段,其他选择器不需要)。
我们指定一个过滤器(尽管可以使用多个过滤器)。 默认情况下将禁用过滤器。
sinput string F = "————— Filter —————"; input SELECTORS Filter1 = SELECTOR_NONE; input TRADE_RECORD_FIELDS Filter1Field = FIELD_NONE; input float Filter1value1 = 0; input float Filter1value2 = 0;
过滤器的理念:仅考虑 Filter1Field 指定字段含有 Filter1value1 指定数值的那些记录(Filter1value2 必须相同,这是在此示例中创建 Filter 对象所必需的)。 请记住,品种或魔幻数字字段的值与词汇表中的索引相对应。
过滤器可以选择不包含数值,但可以包含 Filter1value1 和 Filter1value2 之间的数值范围(如果它们不相等,因为 FilterRange 对象只在两个数值不同时才能创建)。
已经针对过滤可能性演示创建了该实现,该实现可极大地扩展,以便用于未来的实际运用。
我们描述聚合器的另一个枚举:
enum AGGREGATORS { AGGREGATOR_SUM, // 合计 AGGREGATOR_AVERAGE, // 均值 AGGREGATOR_MAX, // 最大 AGGREGATOR_MIN, // 最小 AGGREGATOR_COUNT, // 计数 AGGREGATOR_PROFITFACTOR, // 盈利因子 AGGREGATOR_PROGRESSIVE, // 进步总数 AGGREGATOR_IDENTITY // 标识 };
它作为操作聚合器一组输入参数的描述:
sinput string A = "————— Aggregator —————"; input AGGREGATORS AggregatorType = AGGREGATOR_SUM; input TRADE_RECORD_FIELDS AggregatorField = FIELD_PROFIT_AMOUNT;
所有选择器(包括可选过滤器中使用的选择器)都在 OnInit 中初始化。
int selectorCount; SELECTORS selectorArray[4]; TRADE_RECORD_FIELDS selectorField[4]; int OnInit() { selectorCount = (SelectorX != SELECTOR_NONE) + (SelectorY != SELECTOR_NONE) + (SelectorZ != SELECTOR_NONE); selectorArray[0] = SelectorX; selectorArray[1] = SelectorY; selectorArray[2] = SelectorZ; selectorArray[3] = Filter1; selectorField[0] = FieldX; selectorField[1] = FieldY; selectorField[2] = FieldZ; selectorField[3] = Filter1Field; EventSetTimer(1); return(INIT_SUCCEEDED); }
OLAP 仅由计时器运行一次。
void OnTimer() { process(); EventKillTimer(); } void process() { HistoryDataAdapter history; Analyst<TRADE_RECORD_FIELDS> *analyst; Selector<TRADE_RECORD_FIELDS> *selectors[]; ArrayResize(selectors, selectorCount); for(int i = 0; i < selectorCount; i++) { selectors[i] = createSelector(i); } Filter<TRADE_RECORD_FIELDS> *filters[]; if(Filter1 != SELECTOR_NONE) { ArrayResize(filters, 1); Selector<TRADE_RECORD_FIELDS> *filterSelector = createSelector(3); if(Filter1value1 != Filter1value2) { filters[0] = new FilterRange<TRADE_RECORD_FIELDS>(filterSelector, Filter1value1, Filter1value2); } else { filters[0] = new Filter<TRADE_RECORD_FIELDS>(filterSelector, Filter1value1); } } Aggregator<TRADE_RECORD_FIELDS> *aggregator; // MQL 不支持“类信息” 元类。 // 否则我们可以使用类数组替代 switch switch(AggregatorType) { case AGGREGATOR_SUM: aggregator = new SumAggregator<TRADE_RECORD_FIELDS>(AggregatorField, selectors, filters); break; case AGGREGATOR_AVERAGE: aggregator = new AverageAggregator<TRADE_RECORD_FIELDS>(AggregatorField, selectors, filters); break; case AGGREGATOR_MAX: aggregator = new MaxAggregator<TRADE_RECORD_FIELDS>(AggregatorField, selectors, filters); break; case AGGREGATOR_MIN: aggregator = new MinAggregator<TRADE_RECORD_FIELDS>(AggregatorField, selectors, filters); break; case AGGREGATOR_COUNT: aggregator = new CountAggregator<TRADE_RECORD_FIELDS>(AggregatorField, selectors, filters); break; case AGGREGATOR_PROFITFACTOR: aggregator = new ProfitFactorAggregator<TRADE_RECORD_FIELDS>(AggregatorField, selectors, filters); break; case AGGREGATOR_PROGRESSIVE: aggregator = new ProgressiveTotalAggregator<TRADE_RECORD_FIELDS>(AggregatorField, selectors, filters); break; case AGGREGATOR_IDENTITY: aggregator = new IdentityAggregator<TRADE_RECORD_FIELDS>(AggregatorField, selectors, filters); break; } LogDisplay display; analyst = new Analyst<TRADE_RECORD_FIELDS>(history, aggregator, display); analyst.acquireData(); Print("Symbol number: ", TradeRecord::getSymbolCount()); for(int i = 0; i < TradeRecord::getSymbolCount(); i++) { Print(i, "] ", TradeRecord::getSymbol(i)); } Print("Magic number: ", TradeRecord::getMagicCount()); for(int i = 0; i < TradeRecord::getMagicCount(); i++) { Print(i, "] ", TradeRecord::getMagic(i)); } Print("Filters: ", aggregator.getFilterTitles()); Print("Selectors: ", selectorCount); analyst.build(); analyst.display(); delete analyst; delete aggregator; for(int i = 0; i < selectorCount; i++) { delete selectors[i]; } for(int i = 0; i < ArraySize(filters); i++) { delete filters[i].getSelector(); delete filters[i]; } }
辅助函数 createSelector 定义如下。
Selector<TRADE_RECORD_FIELDS> *createSelector(int i) { switch(selectorArray[i]) { case SELECTOR_TYPE: return new TypeSelector(); case SELECTOR_SYMBOL: return new SymbolSelector(); case SELECTOR_SERIAL: return new SerialNumberSelector(); case SELECTOR_MAGIC: return new MagicSelector(); case SELECTOR_PROFITABLE: return new ProfitableSelector(); case SELECTOR_DURATION: return new DaysRangeSelector(15); // 多达 14 天 case SELECTOR_WEEKDAY: return selectorField[i] != FIELD_NONE ? new WeekDaySelector(selectorField[i]) : NULL; case SELECTOR_DAYHOUR: return selectorField[i] != FIELD_NONE ? new DayHourSelector(selectorField[i]) : NULL; case SELECTOR_HOURMINUTE: return selectorField[i] != FIELD_NONE ? new DayHourSelector(selectorField[i]) : NULL; case SELECTOR_SCALAR: return selectorField[i] != FIELD_NONE ? new TradeSelector(selectorField[i]) : NULL; case SELECTOR_QUANTS: return selectorField[i] != FIELD_NONE ? new QuantizationSelector(selectorField[i]) : NULL; } return NULL; }
除了 DaysRangeSelector 之外的所有类都是从头文件导入的,而 DaysRangeSelector 在 OLAPDEMO 智能交易系统中描述如下:
class DaysRangeSelector: public DateTimeSelector<TRADE_RECORD_FIELDS> { public: DaysRangeSelector(const int n): DateTimeSelector<TRADE_RECORD_FIELDS>(FIELD_DURATION, n) { _typename = typename(this); } virtual bool select(const Record *r, int &index) const override { double d = r.get(selector); int days = (int)(d / (60 * 60 * 24)); index = MathMin(days, granularity - 1); return true; } virtual string getLabel(const int index) const override { return index < granularity - 1 ? ((index < 10 ? " ": "") + (string)index + "D") : ((string)index + "D+"); } };
这是自定义选择器的实现示例。 它将交易仓位按其在市场中的生存周期分组。
如果您在任意帐户上运行该 EA 并选择 2 个选择器,SymbolSelector 和 WeekDaySelector,您可在日志中收到以下结果:
Analyzing account history Symbol number: 5 0] FDAX 1] XAUUSD 2] UKBrent 3] NQ 4] EURUSD Magic number: 1 0] 0 Filters: no Selectors: 2 SumAggregator<TRADE_RECORD_FIELDS> FIELD_PROFIT_AMOUNT [35] X: SymbolSelector(FIELD_SYMBOL) [5] Y: WeekDaySelector(FIELD_DATETIME2) [7] ... 0.000: FDAX Monday 0.000: XAUUSD Monday -20.400: UKBrent Monday 0.000: NQ Monday 0.000: EURUSD Monday 0.000: FDAX Tuesday 0.000: XAUUSD Tuesday 0.000: UKBrent Tuesday 0.000: NQ Tuesday 0.000: EURUSD Tuesday 23.740: FDAX Wednesday 4.240: XAUUSD Wednesday 0.000: UKBrent Wednesday 0.000: NQ Wednesday 0.000: EURUSD Wednesday 0.000: FDAX Thursday 0.000: XAUUSD Thursday 0.000: UKBrent Thursday 0.000: NQ Thursday 0.000: EURUSD Thursday 0.000: FDAX Friday 0.000: XAUUSD Friday 0.000: UKBrent Friday 13.900: NQ Friday 1.140: EURUSD Friday ...
帐户上交易了五个品种。 超立方体大小:35 个单元。 所有品种和星期值的组合与相应的盈利/亏损金额一并显示。 请注意,WeekDaySelector
需要明确指示字段,因为每笔仓位都有两个日期,开仓日期(FIELD_DATETIME1)和平仓日期(FIELD_DATETIME2)。 此处我们选择了 FIELD_DATETIME2。
不仅为了分析当前帐户历史记录,还要分析 HTML 格式的任意交易报告,以及含有 MQL5 信号历史记录的 CSV 文件,我把上一篇文章中的提出的方法(使用
CSS 选择器从 HTML 页面提取结构化数据和如何将基于 HTML 和 CSV 报告的多货币交易历史可视化)添加到 OLAP 函数库中。
已编写的其他层面的类也集成到 OLAP 之中。 特别是,头文件 HTMLcube.mqh 包含交易记录类 HTMLTradeRecord 和继承自 DataAdapter 的 HTMLReportAdapter。 头文件 CSVcube.mqh 相应地包含记录类
CSVTradeRecord 和 CSVReportAdapter。 读取 HTML 由 WebDataExtractor.mqh 负责,而读取 CSV 由 CSVReader.mqh 负责。
下载报告的输入参数,和处理报告的一般原则(包括附加前缀和后缀来选择合适的品种)在上面提到的第二篇文章中有详述。
以下是信号分析结果(CSV 文件)。 我们使用利润因子和品种聚合器来细分。 结果按降序排序:
Reading csv-file ***.history.csv 219 records transferred to 217 trades Symbol number: 8 0] GBPUSD 1] EURUSD 2] NZDUSD 3] USDJPY 4] USDCAD 5] GBPAUD 6] AUDUSD 7] NZDJPY Magic number: 1 0] 0 Filters: no Selectors: 1 ProfitFactorAggregator<TRADE_RECORD_FIELDS> FIELD_PROFIT_AMOUNT [8] X: SymbolSelector(FIELD_SYMBOL) [8] [value] [title] [0] inf "NZDJPY" [1] inf "AUDUSD" [2] inf "GBPAUD" [3] 7.051 "USDCAD" [4] 4.716 "USDJPY" [5] 1.979 "EURUSD" [6] 1.802 "NZDUSD" [7] 1.359 "GBPUSD"
当有盈利且无亏损时,在源代码中生成 inf 值。 如您所见,实际值的比较与其排序是按“无穷大”大于任何其他有限数的方式完成的。
当然,在日志中查看交易报告分析结果并不是很方便。 更好的解决方案是使用 Display 接口实现,它能够以可视化图形的形式呈现超立方体。 尽管其简单明了,但该任务需要准备步骤和大量的繁琐编码。 因此,我们将在本文的第二部分中研究它。
结束语
本文概述著名大数据在线分析(OLAP)方法,可应用在交易操作历史。 利用 MQL,我们实现了基类,这些基类能够依据所选变量(选择器)生成虚拟超立方体,并在其基础上生成各种聚合值。 该机制还可以应用于处理优化结果,根据所选标准选择交易信号,以及利用掌握的知识从大数据里提取算法进行决策的其他区域。
附带文件:
- Experts/OLAP/OLAPDEMO.mq5 — 演示用智能交易系统;
- Include/OLAP/OLAPcube.mqh — 含有 OLAP 类的主头文件;
- Include/OLAP/PairArray.mqh — [数值;名称] 数据对数组,支持所有排序变量;
- Include/OLAP/HTMLcube.mqh — 从 HTML 报告加载数据并与OLAP 相结合;
- Include/OLAP/CSVcube.mqh — 从 CSV 文件加载数据并与OLAP 相结合;
- Include/MT4orders.mqh — MT4orders 函数库,用于在 МТ4 和 МТ5 中按单一风格处理订单;
- Include/Marketeer/WebDataExtractor.mqh — HTML 解析器;
- Include/Marketeer/empty_strings.h — 空的 HTML标签列表;
- Include/Marketeer/HTMLcolumns.mqh — HTML 报告的列索引定义;
- Include/Marketeer/CSVReader.mqh — CSV 解析器;
- Include/Marketeer/CSVcolumns.mqh — CSV 报告的列索引定义;
- Include/Marketeer/IndexMap.mqh — 辅助头文件,实现含键索引数组,以及数组的组合访问;
- Include/Marketeer/RubbArray.mqh — 含有 “rubber” 数组的辅助头文件;
- Include/Marketeer/TimeMT4.mqh — 辅助头文件,以 MetaTrader 4 风格实现数据处理函数;
- Include/Marketeer/Converter.mqh — 用于转换数据类型的辅助头文件;
- Include/Marketeer/GroupSettings.mqh — 辅助头文件,包含输入参数的分组设置。
本文译自 MetaQuotes Software Corp. 撰写的俄文原文
原文地址: https://www.mql5.com/ru/articles/6602
MyFxtops迈投(www.myfxtops.com)-靠谱的外汇跟单社区,免费跟随高手做交易!
免责声明:本文系转载自网络,如有侵犯,请联系我们立即删除,另:本文仅代表作者个人观点,与迈投财经无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。