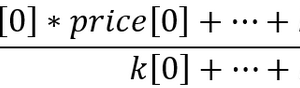简介
技术分析的主要任务之一,就是确定市场的近期走向。从统计学的观点来看,可将其归结为选择指标并确定其值,再以此为根据,有可能将未来市场状况划分为两大类:1) 上行, 2) 下行。
要决定哪类指标、哪些值能够实现上述类别之间更好的判别,判别分析指明了一条路径。换而言之,判别分析让一种可以根据从指标接收的数据预测市场走向的模型构建成为了可能。
但是,该分析相当复杂,要求在输入时提供大量的数据。因此,要用它来人工分析市场状况,会相当费时。幸运的是,有了 MQL5 语言和统计软件,我们即已具备了判别分析数据选择、准备及应用自动化的能力。
本文会给出市场数据采集 EA 开发的一个示例。它可以充当 Statistica 软件中针对外汇市场预后模型构建的应用判别分析的一个教程。
1. 何谓“判别分析”?
判别分析(以下简称为 “DA”)是一种图案识别方法。而神经网络可被视为 DA 的一个特例。基于图案识别的大多数成功的防御系统都采用了 DA。
它允许确定哪些变量会将流入数据划分(判别)为各个组,并查看判别机制。
我们一起看一看针对外汇市场使用 DA 的一个简化示例。我们拥有来自相对强弱指数 (RSI)、MACD 和相对能量指数 (RVI) 指标的数据值,而且我们需要预测价格走向。作为 DA 的结果,我们所得如下。
a. RVI 指标无益于预测。所以我们将其从分析排除。
b. DA 已生成两个判别方程:
- G1 = a1*RSI+b1*MACD+с1,针对价格上涨情况的方程;
- G2 = a1*RSI+b2*MACD+с2,针对价格下跌情况的方程。
在每个柱开始时计算 G1 和 G2 ,如果 G1 > G2,我们预测价格会上涨;而如果 G1 < G2,则预测价格下跌。
DA 可能会证实对初步认识神经网络有帮助。使用 DA 时,我们会得到与神经网络运行计算类似的方程。如此有助于更好地理解其结构,并初步确定是否值得在您的策略中使用神经网络。
2. 判别分析的阶段
这种分析可划分为多个阶段。
- 数据准备;
- 从准备数据中选择最佳变量;
- 利用测试数据分析和测试作为结果的模型;
- 根据判别方程构建模型。
判别分析是专为统计数据分析而设计的几乎所有现代软件包的一部分。其中最流行的是 Statistica (StatSoft Inc. 推出)和 SPSS (IBM Corporation 推出)。我们会利用 Statistica 软件进一步研究判别分析的应用。提供的屏幕截图由 Statistica 8.0 版本获取。软件的早期版本中,这些看起来大致相似。要注意的是:Statistica 还为交易者提供包括神经网络在内的众多其它有用工具。
2.1. 数据准备
数据采集取决于手头的特定任务。我们对任务进行如下定义:利用指标来预测带有已知指标值的柱之后的柱上的价格图表的方向。会针对数据采集开发一个 EA,以将指标值和价格数据保存到某个文件中。
该文件应该是带有下述结构的 CSV 文件。变量应按列排列,每列对应一个特定的指标。行中应包含连续测量值(情况),即特定柱指标的值。换而言之,水平表头包含指标,垂直表头则包含连续柱。
该表应具备一个分组所依据的变量(分组变量)。以本例而论,该变量将基于已获取指标值的指标柱后面的柱上的价格变化。该分组变量应包含数据在同一行中显示的组的数量。比如说,价格上涨的情况用数字 1,价格下跌则用数字 2。
我们将需要下述指标的值:
- 加速动量指标;
- 熊市力量;
- 牛市力量;
- 动量振荡指标;
- 顺势指标;
- DeMarker;
- 分形自适应移动平均线;
- MACD;
- 相对强弱指数;
- 相对能量指数;
- 随机变量;
- 威廉百分比。
OnInit() 函数会创建指标(获取指标句柄)和保存列数据头的 MasterData.csv 文件:
//+------------------------------------------------------------------+ //| EA交易初始化函数 | //+------------------------------------------------------------------+ int OnInit() { //--- 初始化指标 h_AC=iAC(Symbol(),Period()); h_BearsPower=iBearsPower(Symbol(),Period(),BearsPower_PeriodBears); h_BullsPower=iBullsPower(Symbol(),Period(),BullsPower_PeriodBulls); h_AO=iAO(Symbol(),Period()); h_CCI=iCCI(Symbol(),Period(),CCI_PeriodCCI,CCI_Applied); h_DeMarker=iDeMarker(Symbol(),Period(),DeM_PeriodDeM); h_FrAMA=iFrAMA(Symbol(),Period(),FraMA_PeriodMA,FraMA_Shift,FraMA_Applied); h_MACD=iMACD(Symbol(),Period(),MACD_PeriodFast,MACD_PeriodSlow,MACD_PeriodSignal,MACD_Applied); h_RSI=iRSI(Symbol(),Period(),RSI_PeriodRSI,RSI_Applied); h_RVI=iRVI(Symbol(),Period(),RVI_PeriodRVI); h_Stoch=iStochastic(Symbol(),Period(),Stoch_PeriodK,Stoch_PeriodD,Stoch_PeriodSlow,MODE_SMA,Stoch_Applied); h_WPR=iWPR(Symbol(),Period(),WPR_PeriodWPR); if(h_AC==INVALID_HANDLE || h_BearsPower==INVALID_HANDLE || h_BullsPower==INVALID_HANDLE || h_AO==INVALID_HANDLE || h_CCI==INVALID_HANDLE || h_DeMarker==INVALID_HANDLE || h_FrAMA==INVALID_HANDLE || h_MACD==INVALID_HANDLE || h_RSI==INVALID_HANDLE || h_RVI==INVALID_HANDLE || h_Stoch==INVALID_HANDLE || h_WPR==INVALID_HANDLE) { Print("创建指标错误"); return(1); } ArraySetAsSeries(buf_AC,true); ArraySetAsSeries(buf_BearsPower,true); ArraySetAsSeries(buf_BullsPower,true); ArraySetAsSeries(buf_AO,true); ArraySetAsSeries(buf_CCI,true); ArraySetAsSeries(buf_DeMarker,true); ArraySetAsSeries(buf_FrAMA,true); ArraySetAsSeries(buf_MACD_m,true); ArraySetAsSeries(buf_MACD_s,true); ArraySetAsSeries(buf_RSI,true); ArraySetAsSeries(buf_RVI_m,true); ArraySetAsSeries(buf_RVI_s,true); ArraySetAsSeries(buf_Stoch_m,true); ArraySetAsSeries(buf_Stoch_s,true); ArraySetAsSeries(buf_WPR,true); FileHandle=FileOpen("MasterData2.csv",FILE_ANSI|FILE_WRITE|FILE_CSV|FILE_SHARE_READ,';'); if(FileHandle!=INVALID_HANDLE) { Print("FileOpen OK"); //--- 为方便起见保存文件第一行变量的名称 FileWrite(FileHandle,"Time","Hour","Price","AC","dAC","Bears","dBears","Bulls","dBulls", "AO","dAO","CCI","dCCI","DeMarker","dDeMarker","FrAMA","dFrAMA","MACDm","dMACDm", "MACDs","dMACDs","MACDms","dMACDms","RSI","dRSI","RVIm","dRVIm","RVIs","dRVIs", "RVIms","dRVIms","Stoch_m","dStoch_m","Stoch_s","dStoch_s","Stoch_ms","dStoch_ms", "WPR","dWPR"); } else { Print("FileOpen 操作失败. Error",GetLastError()); ExpertRemove(); } //--- return(0); }
OnTick() 事件句柄会识别新柱,并将数据保存于文件中。
价格行为会通过最后一个完成柱来确定,而指标值则会从最后一个完成柱之前的柱获取。除了指标绝对值之外,我们还需要保存绝对值与前一值之间的差异,从而查看变化的方向。示例中提供的此类变量名称均冠以 “d” 前缀。
针对信号线指标,则有必要保存主线与信号线之间的差异,还有其动态。此外,保存新柱的时间和相关的小时值。按时间过滤数据,它迟早都会派上用场。
因此,我们考虑用 37 个指标来构建一个预测模型,从而预测价格的变动。
//+------------------------------------------------------------------+ //| EA交易订单函数 | //| 监控市场情况并在 | //| 每个新柱开端时指标值保存到文件中 | //+------------------------------------------------------------------+ void OnTick() { //--- 声明 datetime 类型静态变量 static datetime Prev_time; //--- 它将被用作保存价格, 交易量和每个柱的点差 MqlRates mrate[]; MqlTick tickdata; ArraySetAsSeries(mrate,true); //--- 取得最近报价 if(!SymbolInfoTick(_Symbol,tickdata)) { Alert("更新报价错误 - 错误: ",GetLastError(),"!!"); return; } ///--- 复制最近4个柱的数据 if(CopyRates(_Symbol,_Period,0,4,mrate)<0) { Alert("复制历史报价错误 - 错误: ",GetLastError(),"!!"); return; } //--- 如果两个时间值相等, 说明有新柱 if(Prev_time==mrate[0].time) return; //--- 把时间保存到静态变量 Prev_time=mrate[0].time; //--- 使用指标值填充数组 bool copy_result=true; copy_result=copy_result && FillArrayFromBuffer1(buf_AC,h_AC,4); copy_result=copy_result && FillArrayFromBuffer1(buf_BearsPower,h_BearsPower,4); copy_result=copy_result && FillArrayFromBuffer1(buf_BullsPower,h_BullsPower,4); copy_result=copy_result && FillArrayFromBuffer1(buf_AO,h_AO,4); copy_result=copy_result && FillArrayFromBuffer1(buf_CCI,h_CCI,4); copy_result=copy_result && FillArrayFromBuffer1(buf_DeMarker,h_DeMarker,4); copy_result=copy_result && FillArrayFromBuffer1(buf_FrAMA,h_FrAMA,4); copy_result=copy_result && FillArraysFromBuffers2(buf_MACD_m,buf_MACD_s,h_MACD,4); copy_result=copy_result && FillArrayFromBuffer1(buf_RSI,h_RSI,4); copy_result=copy_result && FillArraysFromBuffers2(buf_RVI_m,buf_RVI_s,h_RVI,4); copy_result=copy_result && FillArraysFromBuffers2(buf_Stoch_m,buf_Stoch_s,h_Stoch,4); copy_result=copy_result && FillArrayFromBuffer1(buf_WPR,h_WPR,4); //--- 检查复制数据的正确性 if(!copy_result==true) { Print("复制数据错误"); return; } //--- 把最近两个柱的价格移动保存到文件中 //--- 还有指标的前值 if(FileHandle!=INVALID_HANDLE) { MqlDateTime tm; TimeCurrent(tm); uint Result=0; Result=FileWrite(FileHandle,TimeToString(TimeCurrent()),tm.hour, // 柱的时间 (mrate[1].close-mrate[2].close)/_Point, // 最近两个柱收盘价的差异 buf_AC[2],buf_AC[2]-buf_AC[3], // 前柱的指标值和动态 buf_BearsPower[2],buf_BearsPower[2]-buf_BearsPower[3], buf_BullsPower[2],buf_BullsPower[2]-buf_BullsPower[3], buf_AO[2],buf_AO[2]-buf_AO[3], buf_CCI[2],buf_CCI[2]-buf_CCI[3], buf_DeMarker[2],buf_DeMarker[2]-buf_DeMarker[3], buf_FrAMA[2],buf_FrAMA[2]-buf_FrAMA[3], buf_MACD_m[2],buf_MACD_m[2]-buf_MACD_m[3], buf_MACD_s[2],buf_MACD_s[2]-buf_MACD_s[3], buf_MACD_m[2]-buf_MACD_s[2],buf_MACD_m[2]-buf_MACD_s[2]-buf_MACD_m[3]+buf_MACD_s[3], buf_RSI[2],buf_RSI[2]-buf_RSI[3], buf_RVI_m[2],buf_RVI_m[2]-buf_RVI_m[3], buf_RVI_s[2],buf_RVI_s[2]-buf_RVI_s[3], buf_RVI_m[2]-buf_RVI_s[2],buf_RVI_m[2]-buf_RVI_s[2]-buf_RVI_m[3]+buf_RVI_s[3], buf_Stoch_m[2],buf_Stoch_m[2]-buf_Stoch_m[3], buf_Stoch_s[2],buf_Stoch_s[2]-buf_Stoch_s[3], buf_Stoch_m[2]-buf_Stoch_s[2],buf_Stoch_m[2]-buf_Stoch_s[2]-buf_Stoch_m[3]+buf_Stoch_s[3], buf_WPR[2],buf_WPR[2]-buf_WPR[3]); if(Result==0) { Print("FileWrite 操作错误 ",GetLastError()); ExpertRemove(); } } }
启动 EA 后,MasterData.CSV 文件就会于 terminal_data_directory/MQL5/Files 内被创建。在测试程序中启动 EA 时,该文件就会位于 terminal_data_directory/tester/Agent-127.0.0.1-3000/MQL5/Files。所获取的文件已经可以用于 Statistica 中。
该文件的示例请见 MasterData.CSV。采集 EURUSD H1 从 2011 年 8 月 1 日到 2011 年 10 月 1 日的数据。
要在 Statistica 中打开文件,请如下操作。
- 在 Statistica 中,前往菜单 File > Open,选择文件类型:数据文件,并打开您的文件。
- 离开 Delimited in the Text File Import Type (文本文件导入类型定义)窗口并单击 OK。
- 于打开的窗口中启用下划线项目。
- 请牢记:不管原来有没有,都请将小数点放到 Decimal (小数)分隔符字符字段中。

图 1. 将文件导入 Statistica
单击 OK,则包含我们数据的表即准备就绪。

图 2. Statistica 中的数据库
现在我们根据 Price (价格)变量来创建分组变量。
根据价格行为,我们会挑选出四个组:
- 下降 200 点以上;
- 下降 200 点以内;
- 上升 200 点以内;
- 上升 200 点以上。
要添加新变量,请右键单击 AC 列标题并选择 Add Variable (添加变量)选项。

图 3. 添加新变量
在打开的窗口中,将新变量命名为 “Group”,并添加将 Price 变量转换为组数量的公式。
公式如下:
=iif(v3<=-200;1;0)+iif(v3<0 and v3>-200;2;0)+iif(v3>0 and v3<200;3;0)+iif(v3>=200;4;0)

图 4. 变量的描述
文件已做好判别分析的准备。此文件的示例请见 MasterData.STA。
2.2. 最佳变量的选择
运行判别分析(Statistics(统计)->Multivariate Exploratory Techniques(多变量探索性分析技术) ->Discriminant Analysis (判别分析))。

图 5. 运行判别分析
于打开的窗口中单击 Variables (变量)。
在第一个字段中选择分组变量,而以此为根据执行分组的所有变量,则在第二个字段中。
本例中,Group 变量是在第一个字段中指定,而从指标获取的所有变量及附加变量 Hour (接收数据的时间)则在第二个字段中指定。

图 6. 变量的选择
单击 Select Cases (选择情况)按钮(图 8)。会有一个情况选择(数据行)窗口打开,以备判别分析中使用。如下方屏幕截图所示启用项目(图 7)。
分析仅采用前 700 种情形。剩余情形将随后用于作为结果的预后模型的测试。情形的编号通过变量 V0 设置。我们以这种方式指定情形,树立一个 DA 培训数据的样本。
然后单击 OK。

图 7. 定义培训样本
现在,我们选择要构建预后模型的组。
这里有一个问题我们要注意。DA 有一个弱点,那就是对离群数据敏感。少见但强烈的事件(比如本例中的价格尖峰)可令模型失真。比如说,继意外消息后,市场会以持续数小时的大幅波动作为响应。这种情况下的技术指标值对于预测而言几乎没有作用,但在 DA 中它们仍然被认为非常重要,就是因为存在一个显著的价格变动。所以,在运行 DA 之前,最好先检查数据有无离群值。
为了从我们的示例中排除离群值,我们只分析组 2 与组 3。因为组 1 与组 4 中存在大幅价格波动,指标值中可能有离群值。
所以,单击 Codes for grouping variable (分组变量的代码)(图 8)。并指定待分析组的编号。

图 8. 选择待分析组
启用 Advanced (高级)选项。它能实现稍后阶段所要求的逐步分析。
要运行 DA,请单击 OK。
可能会弹出下述消息。这就意味着选定的某一变量过度,且基本上以其它变量为条件,比如说,是另两个变量的和。
对于从指标获取的数据流而言,极有可能是这样。此类变量的存在会影响到分析的质量。应将其移除。为此,请返回 DA 变量选择窗口,通过一个一个的添加识别过度变量。

图 9. 低公差值消息
之后,会打开一个选择 DA 方法的窗口(图 10)。选择下拉列表中的 Forward Stepwise (向前逐步)。因为指标值的预后作用很小,所以最好利用逐步分析。而组判别模型则会自动逐步构建。
具体而言,每一步都要对所有变量进行检查和评估,以确定哪一个对组之间的判别最有益处。该变量之后会被加入到模型中,然后再重复一遍该过程。实现数据样本之间最佳判别的所有变量,均逐步按指定方式选择。

图 10. 方法选择
单击 OK,就会打开一个窗口,通知您 DA 已成功完成。

图 11. DA 结果窗口
单击模型中的 Summary (摘要):Variables (变量),以继逐步分析之后,查看模型中包含的变量列表。这些都是我们各个组之间的最佳判别变量。注意:生成判别准确度超过 95% (p<0.05) 的变量均以红色显示。与其它变量相关的判别准确度较低。该模型中仅包含生成判别准确度不低于 95% 的变量。
但是,根据统计学的“黄金法则”,只有生成准确度高于 95% 的变量方可使用。因此,我们会将那些未以红色显示的所有变量从分析中剔除。它们分别为 dBulls、Bulls、FrAMA、Hour。要剔除这些变量,请返回选择逐步分析的那个窗口,并在窗口内指定哪些要在单击 Variables (变量)后打开。
重复该分析。单击模型中的 Summary:Variables (变量),我们将再一次看到另三个变量现在显示为非有效数据。它们分别为 DeMarker、Stoch_s、AO。我们也要将它们从分析中剔除。
结果是,我们会得到一个模型,其中包括于各组之间生成准确判别的变量 (p<0.01)。

图 12. 模型中包含的变量
由此,37 个变量中仅有 7 个作为预测最有效的变量,留在了我们的示例中。
此方案允许根据自定义交易系统(包括利用神经网络的系统)进一步开发的技术分析,来选择关键指标。
2.3. 利用测试数据分析和测试作为结果的模型
DA 结束后,我们得到了预后模型及其应用于培训数据的结果。
要查看模型并为判别结果分组,请打开 Classification (分类)选项卡。

图 13. Classification 选项卡
单击 Classification matrix (分类矩阵)以查看包含模型应用于培训数据的结果表。
各行会显示观察到的分类。各列中则包含根据模型计算得出的预测分类。包含准确预测的单元格标以绿色,而不准确的预测则以红色显示。
第一列会以 % 显示预测准确度。

图 14. 培训数据分类
采用培训数据的预测精确度 (Total) 变成了 60%。
我们利用测试数据来测试此模型。为此,请单击 Select (图 13)并指定 v0>700;然后,在未用于构建模型的数据范围内检查该模型。
所得如下:

图 15. 测试数据分类
利用测试样本的预测综合准确度,变成了大致达到 55% 的同一水平。对于外汇市场来说,这已经相当不错了。
2.4. 开发一个交易系统
DA 中的预后模型基于线性方程的系统,而指标值也是按此分类到一个组或其它组中。
要查看这些函数的描述,请前往 DA 结果窗口中的 Classification 选项卡(图 13),并单击 Classification 函数。您会看到一个窗口,其中有一个包含判别方程系数的表。

图 16. 判别方程
我们根据表数据来开发一套双方程的系统:
Group2 = 157.17*AC – 465.64*Bears + 82.24*dBears – 0.006*dCCI + 761.06*dFrAMA + 2418.79*dMACDm + 0.01*dStoch_ms – 1.035
Group3 = 527.11*AC – 641.97*Bears + 271.21*dBears – 0.002*dCCI + 1483.47*dFrAMA – 726.16*dMACDm – 0.034*dStoch_ms – 1.353
要使用此模型,请将指标值插入方程,并计算 Group 值。
预测会涉及到 Group 值较高的组。根据我们的示例,如果 Group2 值大于 Group3 值,则预测在未来一个小时内,价格图表很可能会向下移动。而如果是 Group3 值大于 Group2 值,则预测情况会与上述情况正好相反。
要注意的是:本例中的指标值和分析周期的选择都是很随机的。但即便只有这些数据,也足以证实 DA 的潜力和能量。
总结
应用于外汇市场时,判别分析是一种很有用的工具。可用它来搜索和检查变量的最优集,从而将观测到的指标值分类到不同的预测中。亦可将其用于构建预后模型。
对于不需要太多开发经验的 EA 而言,这些作为判别分析结果构建的模型均可轻松集成。判别分析本身的使用也相对简单。上述的分步教程已足够您分析自己的数据。
有关判别分析的更多详情,请参阅 电子教科书中的相关章节。
本文译自 MetaQuotes Software Corp. 撰写的俄文原文
原文地址: https://www.mql5.com/ru/articles/335
(21.25 KB)
(662.43 KB)
MyFxtop迈投-靠谱的外汇跟单社区,免费跟随高手做交易!
免责声明:本文系转载自网络,如有侵犯,请联系我们立即删除,另:本文仅代表作者个人观点,与迈投财经无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。