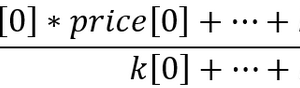简介
在本人的《指标的经济计算原则》一文中,我执行了相当有说服力的测试,证实了并非代码中对于自定义或技术指标的每一次调用,都是某制定指标中执行中间计算的最优方式。
如果我们将中间计算的代码置入指标,其执行速度看似比我们最终的执行速度快很多。
如果能足够简单,那么,这种编写代码的方法会非常诱人。事实上,它似乎成为了那些带有额外缓冲区(用于存储计算中间结果)描述的代码的一种严重并发症。
尽管中间计算的种类繁多,但我们最需要的是平均线的不同算法。大多数情况下,我们都可以针对它们,采用可以极大地简化编写此类代码任务的、简单且普适的自定义函数。本文中,我们会描述创建和使用此类函数的过程。
1. 操作一个柱的平均线函数综述
中间指标缓冲区某个当前柱取平均值的经典方法,我们会填写必要信息,再选择此前值的范围(与平均周期相同),再计算平均值。
处理该选择的流程如下:
SmoothVar(bar) = Function(Var(bar – (n-1)), Var(bar – (n-2)), ………Var(bar))
其中:
- SmoothVar(bar) — 平均参数;
- bar — 执行计算所对应柱的编号;
- Var(bar – (n-1)) — 平均参数,带 (n-1) 柱平移;
- n — 取平均值的柱数。
本例中这种取平均值的方法,会导致两个计算周期的出现。在第一个周期中,数据会被计算并置入某中间缓冲区。而第二个周期内,则会根据上面建议的公式,利用指标缓冲区单元格额外搜索的另一个周期执行平均值获取。如果我们将中间数据选择累积到函数本身当中,则此计算看起来就容易多了。这种情况下,取平均值的函数如下:
SmoothVar(bar) = Function(Var(bar), bar)
一个新值 Var(bar) 被写到当前柱函数内部的选择值,而不再有用的 Var(bar – n) 值则会从选择中被删除。利用这种方法,取平均值的代码看起来就会微乎其微,根本就不需要额外的指标缓冲区。函数内部,数组会存储计算一个柱(而非整个历史数据)所需数据的精确需求量。
本例中,还是只有一个数据计算周期。要注意的是:想要调用当前柱取平均值的这个函数,您首先要在所有前柱上调用它。
2. 作为操作一个柱的函数的实施示例的取平均值的经典方法
此类取平均值函数应包含各种不得在两次调用之间丢失其值的变量。此外,带有不同参数的单型平均线,可多次用于代码当中;因此,要避免使用共享内存资源的冲突,我们要将此类函数作为类实施,我也正是这么做的。
经典平均线算法,会在 CMoving_Average 类中描述:
class CMoving_Average : public CMovSeriesTools { public: double MASeries (uint begin, // 可靠柱的起点索引 uint prev_calculated, // 前一订单时的历史柱数 uint rates_total, // 当前订单时的历史柱数 int Length, // 平均周期数 ENUM_MA_METHOD MA_Method, // 平均方法 (MODE_SMA, MODE_EMA, MODE_SMMA, MODE_LWMA) double series, // 用于计算编号为 'bar' 的价格序列值 uint bar, // 柱索引 bool set // 数组索引方向. ); double SMASeries (uint begin, // 可靠柱的起点索引 uint prev_calculated,// 前一订单时历史柱的数量 uint rates_total, // 当前订单时历史柱的数量 int Length, // 平均周期数 double series, // 用于计算编号为 'bar' 的价格序列值 uint bar, // 柱索引 bool set // 数组索引方向. ); double EMASeries (uint begin, // 可靠柱的起点索引 uint prev_calculated, // 前一订单时历史柱的数量 uint rates_total, // 当前订单时历史柱的数量 double Length, // 平均周期数 double series, // 用于计算编号为 'bar' 的价格序列值 uint bar, // 柱索引 bool set // 数组索引方向. ); double SMMASeries(uint begin, // 可靠柱的起点索引 uint prev_calculated, // 前一订单时的历史柱数量 uint rates_total, // 当前订单时的历史柱数量 int Length, // 平均周期数 double series, // 用于计算编号为 'bar' 的价格序列值 uint bar, // 柱索引 bool set // 数组索引方向. ); double LWMASeries(uint begin, // 可靠柱的起点索引 uint prev_calculated, // 前一订单时的历史柱数量 uint rates_total, // 当前订单时的历史柱数量 int Length, // 平均周期数 double series, // 用于计算编号为 'bar' 的价格序列值 uint bar, // 柱索引 bool set // 数组索引方向. ); protected: double m_SeriesArray[]; int m_Size_, m_count, m_weight; double m_Moving, m_MOVING, m_Pr; double m_sum, m_SUM, m_lsum, m_LSUM; };
该类衍生自基类 CMovSeriesTools,而该基类中包含其它的受保护的函数方法以及对于移动平均周期正确性的检查。
该基类中包含用于我所建议的所有类中的其它通用代码,所以,也就无需将其多次复制到衍生类了。在利用平均线的应用任务中,这些受保护的类成员并未显式使用,所以我们暂且放一放它们的概述。
CMoving_Average 类由 5 个单型平均线函数构成,看名称即可知其各自内容,所以无需我们赘述了。
第一个函数 MASeries() 是其它 4 种允许利用 MA_Method 参数选择平均线算法的函数汇集而成的一个整体。这些平均线算法的代码,均已经过性能最优化;正因如此,函数的主要参数 (Length, series, bar) 补充了额外的参数 begin、prev_calculated、rates_total 和 set,旨在与同名指标变量完全一致。
参数 ‘set’ 会将平均线函数中某价格系列 ‘series’ 的元素索引标志,设置为与变量数组相同。
我们要想到,该类的所有平均线函数都拥有固定的 Length 参数,而且程序代码执行时,不可对其进行更改!CMoving_Average 类的 EMASeries() 函数就拥有双精度类型的该参数!
现在,随着我们对于 CMoving_Average 类的深入了解,可以试着在指标中运用它了。为此,利用 #include 指令,将全局范围的 MASeries_Cls.mqh 文件内容,添加到您所开发的指标代码中去:
#include <MASeries_Cls.mqh>
之后,您要确定指标代码中取平均值流程的必要次数,再于 OnCalculate() 部分(循环运算符与花括号之前),根据取平均值流程的必要次数,声明 CMoving_Average 类的静态变量。取平均值的每个流程中,该类的数组中都必须有一个该类的独立变量和一个独立的单元格。
//---- 声明MASeries_Cls.mqh文件中CMoving_Average类的变量 static CMoving_Average MA1, MA2, MA3, MA4;
OnCalculate() 函数中该类的变量已声明为静态,因为此函数每两次被调用之间,它们的值都须保存。现在,我们可以试着关注取平均值本身了。作为示例,我会展示价格系列 – SMA/EMA/SMMA/LWMA (指标 MAx4.mq5)取平均值的 4 个连续流程:
//---- 指标计算主循环 for(bar = first; bar < rates_total; bar++) { //----+ 调用四次 MASeries 函数. ma1_ = MA1.MASeries(start1, prev_calculated, rates_total, Length1, MODE_SMA, price[bar], bar, false); ma2_ = MA2.MASeries(start2, prev_calculated, rates_total, Length2, MODE_EMA, ma1_, bar, false); ma3_ = MA3.MASeries(start3, prev_calculated, rates_total, Length3, MODE_SMMA, ma2_, bar, false); ma4_ = MA4.MASeries(start4, prev_calculated, rates_total, Length4, MODE_LWMA, ma3_, bar, false); //---- MAx4[bar] = ma4_ + dPriceShift; }
每一个前平均线(不包括最后一个)的结果,都会用于下一个平均线算法中;而且,最终结果会被传递至指标缓冲区。
我觉得,此代码最最关键的部分,就是呈现可靠柱起始的索引变量的、非常谨慎的初步初始化。这种情况下,其所示如下:
//---- 初始化可靠信息起点变量 start1 = 0 + begin; start2 = Length1 + begin; start3 = Length1 + begin; // 之前的 EMA 平均没有改变可靠信息的起点 start4 = Length1 + Length3 + begin;
注意:在这种情况下,平均线的 LWMA 算法是最后一个,不会造成任何影响;但如果它不是最后一个,则可靠信息的起始平移会等于 Length4+1,而不是 Length4!
如果之前代码中的可靠信息起始数字不清晰,则取一个较大值;如有必要,再试着往下递减。
3. 利用类创建的指标,与其利用技术和自定义指标创建的同类物的对比
对于所创建的 MAx4.mq5 指标性能,与其利用技术指标 iMA() 创建的类似物 (iMAx4.mq5) 的对比,将会非常有趣。
只要决定了执行测试,测试与 MAx4.mq5 类似的另一个指标 (MAx3x1.mq5) 便会非常合理 ,只是第一个平均线利用技术指标 iMA() 的调用完成,而其它三个则利用 CMoving_Average 类。而且,只要客户端指标的标准设置中包含 Custom Moving Average.mq5 指标,我就会在其基础上,制作另一个测试用途的类似指标 (cMAx4.mq5)。
针对即将到来的分析,我为测试“EA 交易”所做的准备:分别为 MAx4_Test.mq5、iMAx4_Test.mq5、MAx3x1_Test.mq5 和 cMAx4_Test.mq5。而此类测试的执行条件,详见 《指标的经济计算原则》 一文。我不会在本文中描述测试详情,但会展示过去 12 个月内在 EURUSD Н4 条件下的策略测试程序中所有四个“EA 交易”的最终运行结果,包括每次价格跳动的建模,以及等于 500 的所有 EA “周期”输入参数的值。

我们测试中,最差的结果均由调用自定义指标的指标显示;因此,这种编写代码的变体仅向懒人推荐。当然,另一个最后介绍、基于技术指标调用的“先导”结果要好得多,却仍然不够理想。
这些测试的真正先导指标是利用类开发出来的指标!
利用类和技术指标的混合体位居第二,但它不是总有发生;如果某指标的测试时间很关键,则最好亲自检查此类变量的每一种具体情况。
平均线类实施综述
| № | 算法 | 类名称 | 文件名称 | 应用某算法后, 可靠柱起始的平移 |
Length 参数动态变动 的可能性 |
|---|---|---|---|---|---|
| 1 | 经典平均线 | CMoving_Average | MASeries_Cls.mqh | Length/0/Length/Length + 1 (SMA/EMA/SMMA/LWMA) | 无 |
| 2 | 标准方差 | CStdDeviation | StdDevSeries_Cls.mqh | Length | 无 |
| 3 | JMA 平滑 | CJJMA | JJMASeries_Cls.mqh | 30 | 有 |
| 4 | T3 平滑 | CT3 | T3Series_Cls.mqh | 0 | 有 |
| 5 | 超线性平滑 | CJurX | JurXSeries_Cls.mqh | 0 | 有 |
| 6 | 图莎尔·钱德平滑 | CCMO | CMOSeries_Cls.mqh | Length + 1 | 无 |
| 7 | 考夫曼平滑 | CAMA | AMASeries_Cls.mqh | Length + 3 | 无 |
| 8 | 抛物线平均线 | CParMA | ParMASeries_Cls.mqh | Length | 无 |
| 9 | 变速 | CMomentum | MomSeries_Cls.mqh | Length + 1 | 无 |
| 10 | 变速标准化 | CnMomentum | nMomSeries_Cls.mqh | Length + 1 | 无 |
| 11 | 变动率 | CROC | ROCSeries_Cls.mqh | Length + 1 | 无 |
前面讲到的 CMoving_Average 类包含五个平均线算法。
CCMO 类包含平均线的算法与动量指标。
其它类则包含单个的平均线算法。使用任何推荐类的思想体系,与上述使用 CMoving_Average 类的流程完全相同。所有平均线(抛物线除外)算法的代码,均经过最大执行速度方面的优化。鉴于该过程的复杂性,抛物线平均线的代码并未优化。最后三个算法并不呈现平均线。之所以我还添加它们,是因为它们的高普及性,以及在受欢迎的技术分析师作品中的兼容性。
为了让信息更容易理解,最好是在各个独立的 .mqh 文件中呈现平均线算法;而且,出于实用考虑,最好的变量都是将其纳入独立文件。
要在指标中使用的话,所有建议的类都会被封装于 SmoothAlgorithms.mqh 单文件中。此外,该文件还会补充 iPriceSeries.mqh 文件的函数。本文示例中只采用了 PriceSeries() 函数:
double PriceSeries ( uint applied_price, // 价格常数 uint bar, // 指定周期数向前或者向后转换的索引 // 相对当前柱. const double& Open [], const double& Low [], const double& High [], const double& Close[] )
此函数旨在基于 OnCalculate() 函数第二种调用类型的使用,来操作指标。
创建此函数的主旨,在于利用自定义变量拓展 ENUM_APPLIED_PRICE 枚举的价格时间序列集。此函数会按其从 1 到 11 的数字,返回某价格时间序列的值。
4. 利用平均线类实施某程序代码的实用示例
如果还够显示利用其它类的另一示例,则一定要确保所有事情均以与四倍平均线相同的方式完成。我会利用 CJJMA 和 CJurX (JCCX.mq5) 类,在 CCI 指标的某个类似物中,显示 OnCalculate() 函数实施的某个变量。
int OnCalculate(const int rates_total, // 当前订单时的历史柱数 const int prev_calculated, // 之前订单时的历史柱数 const datetime& time[], const double& open[], const double& high[], const double& low[], const double& close[], const long& tick_volume[], const long& volume[], const int& spread[] ) { //----+ //---- 检查是否有足够的柱数用于计算 if (rates_total < 0) return(0); //---- 声明浮点型变量 double price_, jma, up_cci, dn_cci, up_jccx, dn_jccx, jccx; //----+ 声明整型变量 int first, bar; //---- 计算在柱的重计算循环中的起点编号 'first' if (prev_calculated == 0) // 检查指标计算的第一个起点 first = 0; // 计算所有柱的起点编号 else first = prev_calculated - 1; // 计算新柱的起点编号 //---- 声明 SmoothAlgorithms.mqh 文件中 CJurX 类的变量 static CJurX Jur1, Jur2; //---- 声明 SmoothAlgorithms.mqh 文件中 CJMA类的变量 static CJJMA JMA; //---- 计算指标的主循环 for(bar = first; bar < rates_total; bar++) { //----+ 调用 PriceSeries 函数以取得输入价格 price_ price_ = PriceSeries(IPC, bar, open, low, high, close); //----+ 调用 JJMASeries 函数以取得 JMA jma = JMA.JJMASeries(0, prev_calculated, rates_total, 0, JMAPhase, JMALength, price_, bar, false); //----+ 确定JMA 值的价格偏移 up_cci = price_ - jma; dn_cci = MathAbs(up_cci); //----+ 调用 JurXSeries 函数两次. up_jccx = Jur1.JurXSeries(30, prev_calculated, rates_total, 0, JurXLength, up_cci, bar, false); dn_jccx = Jur2.JurXSeries(30, prev_calculated, rates_total, 0, JurXLength, dn_cci, bar, false); //---- 防止空值时出现除零错误 if (dn_jccx == 0) jccx = EMPTY_VALUE; else { jccx = up_jccx / dn_jccx; //---- 给指标加以限制在顶部和底部之间 if (jccx > +1)jccx = +1; if (jccx < -1)jccx = -1; } //---- 把取得的值载入指标缓冲区 JCCX[bar] = jccx; } //----+ return(rates_total); }

但这次,我是把来自全局范围另一份文件的相应类,添加到指标代码中:
#include <SmoothAlgorithms.mqh>
现在,请留意另一件事情。有超大量的指标可以表示为一个柱的函数,再利用类来操作它们,真的是非常轻松。
比如说,根据图莎尔·钱德的 Vidya (弹性指数动态平均)移动平均线来绘制布林通道会很有趣。本例中采用了 CCMO 与 CStdDeviation 两个类。我们利用第一个类获取移动平均线 VIDYA 的值;再利用第二个类,计算移动平均线价格系列的标准方差值。
此后,我们再将此方差用于通道上下边界的计算:
//+------------------------------------------------------------------+ // CStdDeviation{}; 和 CCMO{}; 的类描述 | //+------------------------------------------------------------------+ #include <SmoothAlgorithms.mqh> //+==================================================================+ //| 根据移动平均 VIDYA 取得布林 | //| 通道的算法 | //+==================================================================+ class CVidyaBands { public: double VidyaBandsSeries(uint begin, // 用于计算的可靠柱的起点编号 uint prev_calculated, // 前一订单时的历史柱数 uint rates_total, // 当前订单时的历史柱数 int CMO_period, // CMO 振荡器的平均周期数 double EMA_period, // EMA 平均周期数 ENUM_MA_METHOD MA_Method, // averaging 平均类型 int BBLength, // 布林通道的平均周期数 double deviation, // 点差 double series, // 根据'柱'编号计算的价格序列值 uint bar, // 柱索引 bool set, // 数组索引方向 double& DnMovSeries, // 当前柱的通道下轨数值 double& MovSeries, // 当前柱的通道中轨数值 double& UpMovSeries // 当前柱的通道上轨数值 ) { //----+ //----+ 计算中线 MovSeries = m_VIDYA.VIDYASeries(begin, prev_calculated, rates_total, CMO_period, EMA_period, series, bar, set); //----+ 计算布林通道 double StdDev = m_STD.StdDevSeries(begin+CMO_period+1, prev_calculated, rates_total, BBLength, deviation, series, MovSeries, bar, set); DnMovSeries = MovSeries - StdDev; UpMovSeries = MovSeries + StdDev; //----+ return(StdDev); } protected: //---- 声明 CCMO 和 CStdDeviation 类的变量 CCMO m_VIDYA; CStdDeviation m_STD; };
这样一来,我们就得到了一个简小的类!
VidyaBandsSeries() 函数的最后三个输入参数,会通过一个链接传递必要的通道值。
本例中我想提醒大家的是,您不能在 VidyaBandsSeries() 函数中声明类的变量并赋予静态,因为类中的静态变量的意义已经截然不同了。正因如此,该声明务必须在类的全局范围内进行:
protected: //---- 声明 CCMO 和 CStdDeviation 类的变量 CCMO m_VIDYA; CStdDeviation m_STD;
在一个常规的布林通道中,移动平均线的平均周期通常都与通道本身的平均周期相同。
我们已于此类中分别制作了上述参数,为您留出更大的自由(EMA_period 与 BBLength)。基于此类制作的指标本身 (VidyaBBands.mq5),在利用 CVidyaBands 类的过程中也非常简单,以至于我们无需在本文中对其代码进行分析。
指标函数的这些类,均应置入独立的 mqh 文件中。我已经将此类函数放入到 IndicatorsAlgorithms.mqh 文件中。

5. 采用类的指标与未采用类的指标的性能对比
首先,我想弄清楚,在编写指标代码时,使用类会在多大程度上降低其性能?
出于此目的,JJMA.mq5 指标的代码在不利用类的情况下编写而成 (JMA.mq5),再利用此前测试的相同条件对其进行测试。测试的最终结果没有太大的差别:

当然,使用这些类会有一些额外的收费,但同它们提供的好处相比,这点小钱根本微不足道。
6. 使用平均线类的优势
使用这些算法的其中一个优势确实令人信服:就是取代了技术与自定义指标的调用,从而实现了上述开发代码性能的极大提升。
这些类的另一个实用优势,即在于它们使用起来的绝佳便利性。比如说,由 William Blau 编著的畅销书《动量、方向和背离》中所介绍的一切内容,看起来都是此类指标编写方法的真实演练场。指标的代码都经过最大程度的压缩、能够理解且通常还包含一个单周期的柱重新计算。
利用这种平均线替代方法,您可以轻松开发任何指标 – 无论是经典型还是技术型。种类繁多的平均线算法,会为创建非传统交易系统提供广泛的可能性,而且通常能够提前探测出趋势和少量的错误触发。
7. 在特定指标代码中使用平均线算法的一些相关建议
这里讲到的利用不同平均线算法开发出的任何指标,只需看一眼,就能知道这些算法有何不同。

因此,有理由认为并非所有建议的算法在每种情境下都一样好。尽管为使用某种或另一种算法设定一个严格的限制可能很难,但就其使用的问题为您提供一些一般性的建议还是可能的。
比如说,图莎尔·钱德与考夫曼的算法都是旨在确定趋势情况,并不适用于出于噪音滤除考虑的额外平滑。因此,最好是在不取这些算法平均值的情况下,输入未经处理的价格系列或是指标值。此为利用考夫曼算法,Momentum 指标值处理的结果(指标 4c_Momentum_AMA.mq5)。

我觉得经典的平均线算法就不需要特别推荐了。它们的应用领域极其广泛。只要是利用上述算法的地方,您都可以成功运用剩下的四种算法(JMA、T3、超线性与抛物线)。此为 MACD 指标示例,其中的 EMA 与 SMA 均由 JMA 平均线代替(指标 JMACD.mq5):

这个是计算得出指标的平滑结果,而不是替换其平均线算法以达到对当前趋势更好的确认效果(指标 JMomentum.mq5):

市场行为持续变化不是什么新鲜事;因此,要找到金融市场某特定部分绝无仅有的理想算法而一劳永逸,太过天真了。唉!这个世界上没有什么会永恒的!虽然这么说,但以我为例,在这个不断变化的市场中,我通常都会使用快速及中期趋势指标,比如 JFATL.mq5 和 J2JMA.mq5 等。我对以此为基础的预测都非常满意。
我想说再说一件事:平均线算法可重复使用。重复地将平均线应用于已经平均的值,可以取得不错的效果。实际上,我在本文中就是从它开始分析指标绘制的过程(指标 MAx4.mq5)。
8. 平均线算法代码编写综述
现在,在本文快要结尾的时候,我想请您关注一下平均线自身函数的机制。
首先,大多数平均线算法都包含 m_SeriesArray[] 型变量的动态数组,用于存储输入参数 ‘series’ 的值。
只要计算相关重要信息一出现,您就要一次性地为该数组分配内存。此举会利用 CMovSeriesTools 类的 SeriesArrayResize() 函数完成。
//----+ 改变变量数组的大小 if(bar==begin && !SeriesArrayResize(__FUNCTION__, Length, m_SeriesArray, m_Size_)) return(EMPTY_VALUE);
之后,您要针对每个柱,完成价格系列 ‘series’ 当前值到数组最老值的写入,并于 m_count 变量中记忆其位置编号。此举会利用 CMovSeriesTools 类的 Recount_ArrayZeroPos() 函数完成。
//----+ m_SeriesArray 数组单元的转移和初始化
Recount_ArrayZeroPos(m_count, Length_, prev_calculated, series, bar, m_SeriesArray);
而现在,如果我们需要查找一个较当前元素有相对平移的元素,我们则应使用 CMovSeriesTools 类的 Recount_ArrayNumber() 函数:
for(iii=1; iii<=Length; iii++, rrr--) { kkk = Recount_ArrayNumber(m_count, Length_, iii); m_sum += m_SeriesArray[kkk] * rrr; m_lsum += m_SeriesArray[kkk]; m_weight += iii; }
一般来讲,这种情况下,最新的元素会被写到零位,而其它的(除了最老的元素)都会轮流被覆写到下一个位置;但是,它并不节约计算机资源,而上面讲到的更加复杂的方法似乎却要合理得多!
除了平均线算法外,这些函数的主体中还包含用于确定相对于柱计算起始的柱位置的函数调用。
//----+ 检查可靠用于计算的起点 if(BarCheck1(begin, bar, set)) return(EMPTY_VALUE);
一旦启动变量初始化的信息足够:
//----+ 初始化零值 if(BarCheck2(begin, bar, set, Length))
且在最后一个柱已平仓的情况下:
//----+ 保存变量值 if(BarCheck4(rates_total, bar, set))
或未平仓的情况下:
//----+ 恢复变量值 if(BarCheck5(rates_total, bar, set))
第一次检查会确定柱尚不足以令平均线函数工作的情况,且其返回结果为空。一旦第二次检查成功通过,且存在足够的数据进行第一次计算,则变量初始化执行一次。为根据当前未平仓柱正确进行多重处理,还必需做两次最后的检查。我在专门讲解程序代码优化的文章中讲过这一点。
而现在,关于此类函数程序代码优化以实现性能最大化,再说几句。比如说,SMA 算法意味着每个柱一个价格系列周期被选定值的平均数。将这些值实际相加,再除以每个柱的周期。
但是,前一柱求和与当前柱求和的差别在于:第一个是价格系列值与相对于当前周期平稳的总和,而第二个则是与当前值的总和。因此,函数初始化期间仅计算此和一次,然后再针对每个柱、在此总和的基础上加上价格系列的新值,再减去最老值,这样要合理得多。此举完全是在这样一个函数中完成的。
总结
建议文中实施的平均线算法,不论单型与通用,都采用简单的类,以让您学习起来没有困难。
随附于本文的档案中包含大量的示例,能够便于您理解指标代码的这种编写方法。Include__zh.zip 档案中所有的类均分布于各个文件中。Include_zh.zip 档案中只包含足够 Indicators.zip 所有指标编译使用的两份文件。测试用“EA 交易”在 Experts.zip 档案中。
本文译自 MetaQuotes Software Corp. 撰写的俄文原文
原文地址: https://www.mql5.com/ru/articles/180
(5.03 KB)
(48.95 KB)
(21.87 KB)
(103.07 KB)
MyFxtop迈投-靠谱的外汇跟单社区,免费跟随高手做交易!
免责声明:本文系转载自网络,如有侵犯,请联系我们立即删除,另:本文仅代表作者个人观点,与迈投财经无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。