什么是“支持向量机”?
支持向量机(SVM)是一种机器学习方法,试图将输入数据划分为两类。为了使支持向量机有效,第一步是利用一系列训练输入输出数据建立支持向量机模型(用于新的数据分类)。
支持向量机(SVM)模型是通过获取训练输入建立,映射到多维空间,并利用回归算法找到一个超平面,最好能单独两种类型的输入数据(超平面是一个平面将空间分为两个半空间的n维佩斯)一旦完成了训练支持向量机,它可以评估超平面划分相关的新的输入数据并把它们归为一类。
支持向量机本质上是一个输入/输出机器。用户可以输入数据并基于训练模型返回输出。在理论上,任何给定的输入数据,支持向量机可以支持从1到无限范围的数量;然而,在实际应用中,计算能力确实已经成为输入数据使用的瓶颈。例如,当N输入的数据被用在一个特定的支持向量机(n是自然数1和无穷大之间),支持向量机必须映射每个输入数据组n维空间,找到n-1-dimensional超平面,最好能单独训练数据。

图1。支持向量机是一种输入/输出机器。
概念化支持向量机的最佳方法是以二维空间为例。假设我们要创建一个支持向量机有两个输入参数并返回一个输出(将数据分为两类)。我们可以通过绘制下面的2维图表来证明这一点。

图2。左:支持向量机的输入数据映射到2D图。红色圆圈和蓝色叉用来表示两种输入参数。
图3。右:支持向量机的输入数据映射到2D图。红色圆圈和蓝色叉用来表示两种输入参数。黑线表示超平面。
在该示例中,蓝色叉表示属于类型1的数据点,并且红色圆圈表示属于类型2的数据点。每个数据点具有唯一的输入1值(对应于x轴坐标)和输入2值(对应于y轴坐标)。将所有数据点映射到2D空间。
支持向量机可以通过在2D空间中建立数据点模型来对数据进行分类。通过观察二维空间中的数据,支持向量机使用回归算法找到一维超平面(也称为直线),它可以最准确地将数据划分为两种类型。然后利用该分割线将新的数据点划分为1个或2个类别。
下面的动态图示出了支持向量机的一种新的训练过程。该算法将随机地找到一个分割超平面,然后提高超平面的重复精度。正如你所看到的,算法首先波动很大,然后逐渐减慢到所需的解决方案。

图4。示出支持向量机训练过程的动态图。超平面逐步收敛,以实现两种类型的数据之间的几何区别。
上面所示的二维空间允许我们可视化支持向量机的处理,但是它只能使用两个输入数据对数据点进行分类。如果你想使用更多的输入数据?幸运的是,支持向量机算法允许我们在更高的维度上做同样的事情,虽然概念上更难解释。
想一想:你想创建20个输入数据,并且能够使用这些输入将任何数据点分成1型或2型。为此,支持向量机(SVM)在20维空间中建模数据,并使用回归算法来找到将数据点分成两类的19维超平面。这是非常困难的可视化上述情况,因为我们很难理解上述三维空间。不管怎样,你只需要知道它的工作原理与二维空间完全一样。
支持向量机的工作原理:这是Schnick吗?
想象一下,你是一个研究一种稀有动物Snkes的研究者,它只在北极深处徘徊。因为受试者是罕见的,只有少数被发现(假设大约5000个)。作为一个研究者,你对这个问题感到困惑:我怎么能把它识别为Snink?
你只有一些其他研究人员写的论文,他们看到了这只动物。在这些研究论文中,作者描述了他们发现的一些特征,包括身高、体重、四肢数目等。然而,每一篇论文的特点是不同的,没有明显的模式。
我们如何利用这些数据来判断一个新的动物是否是Snink?
支持向量机(SVM)很可能成为解决这一问题的方法之一。基于支持向量机的识别数据模式,一个框架模型来区分动物是否是Schnick或非schnick。第一步是创建一系列数据来训练你的支持向量机来区分Snink。训练数据是一系列的输入参数匹配的支持向量机分析和提取模式输出结果。
因此,我们必须决定使用哪些输入参数和它们的数目。在理论上,我们可以得到输入参数所需的数量,但这往往会放慢训练速度(更多的参数,较长的SVM提取模式的时间)。同时,您希望在所有Snink中选择更一致的输入值。例如,一个动物的身高或体重会是一个很好的输入选择,因为你希望schnicks对这些价值观是相对稳定的。然而,平均年龄并不是一个好的选择,正如你所知道的,被鉴定的动物之间的年龄差距可能非常大。
因此,我们选择下列输入参数:
- 高度
- 重量
- 肢体数
- 目数
- 前肢长度
- 平均行驶速度
- 交配呼叫频率
通过上述输入参数的选择,我们开始编译熟练的数据。有效的训练数据必须满足支持向量机的以下具体条件。
- 数据必须包含Snink的案例。
- 数据必须包含非Snink动物的病例。
在这种情况下,我们从谁已经成功地确定schnick和上市相关属性的科学家取得的研究论文。因此,我们可以阅读研究论文,并提取数据从每个输入,然后分配真实或虚假的输出到每一种情况。本示例中的训练数据可以类似于下表。
| 培训抽样 | 高度[毫米] | 体重[公斤] | 小腿 | n-眼 | L-臂[mm ] | AV速度[米/秒] | FE-LAD[HZ] | Schnick(真/假) |
|---|---|---|---|---|---|---|---|---|
| 例1 | 一千零三十 | 四十五 | 八 | 三 | 四百二十 | 二点一 | 一万四千 | 真的 |
| 例2 | 一千零一十 | 四十二 | 八 | 三 | 四百五十 | 二点二 | 一万四千 | 真的 |
| 例3 | 九百 | 四十 | 七 | 六 | 六百 | 六 | 一万三千 | 错误的 |
| 例4 | 一千零五十 | 四十三 | 九 | 四 | 四百 | 二点四 | 一万二千 | 真的 |
| 例5 | 七百 | 三十五 | 二 | 八 | 三百二十 | 二十一 | 一万三千五百 | 错误的 |
| 例6 | 一千零七十 | 四十二 | 八 | 三 | 四百三十 | 二点四 | 一万二千 | 真的 |
| 例7 | 一千一百 | 四十 | 八 | 三 | 四百三十 | 二点一 | 一万一千 | 真的 |
| 例n | … | … | … | … | … | … | … | … |
表1。施尼克数据表
一旦我们收集了所有的训练输入和输出数据,我们可以使用它来训练我们的支持向量机。在培训过程中,支持向量机会创建17维模型进行各种培训的例子为真假。支持向量机(SVM)不断创造机会,直到一个模型,准确地代表训练数据(在规定的误差允许范围内)获得。训练结束后,该模型可用于处理新的数据点,并根据真假进行分类。
支持向量机工作吗?
在Schnick的帮助下,我编写了一个脚本来测试SVM如何处理新的Snink。完成这个测试,我使用了支持向量机的学习工具库(可在应用市场下载)。
为了有效地模拟这种情况,我们首先决定哪些是Snink的实际特性。我假设的这些属性在下表中列出。如果一个动物满足以下所有标准,那就是Schnick…
| 参数 | 下限 | 上限 |
|---|---|---|
| 高度[毫米] | 一千 | 一千一百 |
| 体重[公斤] | 四十 | 五十 |
| 小腿 | 八 | 十 |
| n-眼 | 三 | 四 |
| L-臂[mm ] | 四百 | 四百五十 |
| AV速度[米/秒] | 二 | 二点五 |
| FE-LAD[HZ] | 一万一千 | 一万五千 |
表2。总结了Snink的参数。
现在我们定义Schnick,我们可以使用这个定义来测试支持向量机。第一步是创建一个函数检索七输入从一个给定的动物然后返回一个动物,schnick或不实际的分类结果。这个函数将被用来生成支持向量机训练数据和评估性能的支持向量机在结束。可以实现以下功能:
//+------------------------------------------------------------------+ //| This function takes the observation properties of the observed //| animal and based on the criteria we have chosen, returns true/false whether it is a schnick //+------------------------------------------------------------------+ bool isItASchnick(double height,double weight,double N_legs,double N_eyes,double L_arm,double av_speed,double f_call) { if(height < 1000 || height > 1100) return(false); // If the height is outside the parameters > return(false) if(weight < 40 || weight > 50) return(false); // If the weight is outside the parameters > return(false) if(N_legs < 8 || N_legs > 10) return(false); // If the N_Legs is outside the parameters > return(false) if(N_eyes < 3 || N_eyes > 4) return(false); // If the N_eyes is outside the parameters > return(false) if(L_arm < 400 || L_arm > 450) return(false); // If the L_arm is outside the parameters > return(false) if(av_speed < 2 || av_speed > 2.5) return(false); // If the av_speed is outside the parameters > return(false) if(f_call < 11000 || f_call > 15000) return(false); // If the f_call is outside the parameters > return(false) return(true); // Otherwise > return(true) }
下一步是创建一个生成训练输入和输出的函数。本示例中的输入将通过在七个输入值的相应设置内创建随机数来生成。然后,对于每组随机生成的输入,使用上述ISITASCHNICK()函数来生成期望的输出。这是通过以下功能完成的:
//+------------------------------------------------------------------+ //| This function takes an empty double array and an empty boolean array, //| and generates the inputs/outputs to be used for training the SVM //+------------------------------------------------------------------+ void genTrainingData(double &inputs[],bool &outputs[],int N) { double in[]; // Creates an empty double array to be used for temporarily storing the inputs generated ArrayResize(in,N_Inputs); // Resize the in[] array to N_Inputs ArrayResize(inputs,N*N_Inputs); // Resize the inputs[] array to have a size of N*N_Inputs ArrayResize(outputs,N); // Resize the outputs[] array to have a size of N for(int i=0;i<N;i++) { in[0]= randBetween(980,1120); // Random input generated for height in[1]= randBetween(38,52); // Random input generated for weight in[2]= randBetween(7,11); // Random input generated for N_legs in[3]= randBetween(3,4.2); // Random input generated for N_eyes in[4]= randBetween(380,450); // Random input generated for L_arms in[5]= randBetween(2,2.6); // Random input generated for av_speed in[6]= randBetween(10500,15500); // Random input generated for f_call ArrayCopy(inputs,in,i*N_Inputs,0,N_Inputs); // Copy the new random inputs generated into the training input array outputs[i]=isItASchnick(in[0],in[1],in[2],in[3],in[4],in[5],in[6]); // Assess the random inputs and determine if it is a schnick } } //+------------------------------------------------------------------+ //| This function is used to create a random value between t1 and t2 //+------------------------------------------------------------------+ double randBetween(double t1,double t2) { return((t2-t1)*((double)MathRand()/(double)32767)+t1); }
现在我们有了一系列的输入和输出参数,是时候使用支持向量机的“应用市场”学习工具创建支持向量机了。只要建立了新的支持向量机,就必须把训练输入和输出参数传递给它,并执行训练。
void OnStart() { double inputs[]; // Empty double array to be used for creating training inputs bool outputs[]; // Empty bool array to be used for creating training inputs int N_TrainingPoints=5000; // Defines the number of training samples to be generated int N_TestPoints=5000; // Defines the number of samples to be used when testing genTrainingData(inputs,outputs,N_TrainingPoints); //Generates the inputs and outputs to be used for training the SVM int handle1=initSVMachine(); // Initializes a new support vector machine and returns a handle setInputs(handle1,inputs,7); // Passes the inputs (without errors) to the support vector machine setOutputs(handle1,outputs); // Passes the outputs (without errors) to the support vector machine setParameter(handle1,OP_TOLERANCE,0.05); // Sets the error tolerance parameter to <5% training(handle1); // Trains the support vector machine using the inputs/outputs passed }
现在,我们有一个支持向量机,并且已经完成了良好的训练,它可以成功地区分Schnick。为了验证这一点,我们可以测试最终的支持向量机来分类新的数据点。首先,可以生成随机输入,然后使用isItASchnick()函数确定这些输入是否对应于实际的Schnick,然后使用支持向量机对输入进行划分,并确定预测结果是否与实际结果一致。这是通过以下功能完成的:
//+------------------------------------------------------------------+ //| This function takes the handle for the trained SVM and tests how //| successful it is at classifying new random inputs //+------------------------------------------------------------------+ double testSVM(int handle,int N) { double in[]; int atrue=0; int afalse=0; int N_correct=0; bool Predicted_Output; bool Actual_Output; ArrayResize(in,N_Inputs); for(int i=0;i<N;i++) { in[0]= randBetween(980,1120); // Random input generated for height in[1]= randBetween(38,52); // Random input generated for weight in[2]= randBetween(7,11); // Random input generated for N_legs in[3]= randBetween(3,4.2); // Random input generated for N_eyes in[4]= randBetween(380,450); // Random input generated for L_arms in[5]= randBetween(2,2.6); // Random input generated for av_speed in[6]= randBetween(10500,15500); // Random input generated for f_call Actual_Output=isItASchnick(in[0],in[1],in[2],in[3],in[4],in[5],in[6]); // Uses the isItASchnick fcn to determine the actual desired output Predicted_Output=classify(handle,in); // Uses the trained SVM to return the predicted output. if(Actual_Output==Predicted_Output) { N_correct++; // This statement keeps count of the number of times the predicted output is correct. } } return(100*((double)N_correct/(double)N)); // Returns the accuracy of the trained SVM as a percentage }
建议在不同的条件下,使用上述函数的值来测试SVM的工作模式。
为什么支持向量机如此有用?
使用支持向量机从数据中提取复杂模式的优点是不需要事先知道数据的行为。一个支持向量机可以分析数据并提取自己的发现和关系。函数处理类似于黑盒,用于获得输入和生成输出。输出可以证明是非常有用的发现数据模式,这通常是非常复杂和非常不清楚。
支持向量机的最佳功能之一是很好地处理数据误差和噪声。他们经常发现数据中的潜在模式、过滤异常值和其他复杂情况。假设下面的情景,在研究Schnick的过程中,你得到了许多研究论文,它们的特性有非常不同的描述(例如,Schnick是200公斤,15米高)。
这样的错误扭曲了Snink模型,并且可能导致新发现的Snkes分类错误。支持向量机的优点是它可以建立一个模型:它符合与满足所有训练数据点的模型相反的基本模式。该模型得到了一定的容错能力,使得支持向量机能够忽略数据中的任何错误。
在Snink支持向量机的情况下,如果我们的容错率是5%,那么训练将尝试建立满足训练数据的95%的模型。因为训练可以忽略一小部分数据的异常,这110有用。
我们可以修改Schnick脚本来进一步识别支持向量机的这个属性。在训练数据集中引入了以下函数来引入人工生成的随机误差。该函数将随机选择训练点,并用随机变量替换输入和输出。
//+------------------------------------------------------------------+ //| This function takes the correct training inputs and outputs generated //| and inserts N random errors into the data //+------------------------------------------------------------------+ void insertRandomErrors(double &inputs[],bool &outputs[],int N) { int nTrainingPoints=ArraySize(outputs); // Calculates the number of training points int index; // Creates new integer 'index' bool randomOutput; // Creates new bool 'randomOutput' double in[]; // Creates an empty double array to be used for temporarily storing the inputs generated ArrayResize(in,N_Inputs); // Resize the in[] array to N_Inputs for(int i=0;i<N;i++) { in[0]= randBetween(980,1120); // Random input generated for height in[1]= randBetween(38,52); // Random input generated for weight in[2]= randBetween(7,11); // Random input generated for N_legs in[3]= randBetween(3,4.2); // Random input generated for N_eyes in[4]= randBetween(380,450); // Random input generated for L_arms in[5]= randBetween(2,2.6); // Random input generated for av_speed in[6]= randBetween(10500,15500); // Random input generated for f_call index=(int)MathRound(randBetween(0,nTrainingPoints-1)); // Randomly chooses one of the training inputs to insert an error if(randBetween(0,1)>0.5) randomOutput=true; // Generates a random boolean output to be used to create an error else randomOutput=false; ArrayCopy(inputs,in,index*N_Inputs,0,N_Inputs); // Copy the new random inputs generated into the training input array outputs[index]=randomOutput; // Copy the new random output generated into the training output array } }
这个函数允许我们在训练数据中人为地引入错误。利用这些带有误差的数据,我们可以创建和训练新的支持向量机,并将其性能与原来的向量机进行比较。
void OnStart() { double inputs[]; // Empty double array to be used for creating training inputs bool outputs[]; // Empty bool array to be used for creating training inputs int N_TrainingPoints=5000; // Defines the number of training samples to be generated int N_TestPoints=5000; // Defines the number of samples to be used when testing genTrainingData(inputs,outputs,N_TrainingPoints); // Generates the inputs and outputs to be used for training the svm int handle1=initSVMachine(); // Initializes a new support vector machine and returns a handle setInputs(handle1,inputs,7); // Passes the inputs (without errors) to the support vector machine setOutputs(handle1,outputs); // Passes the outputs (without errors) to the support vector machine setParameter(handle1,OP_TOLERANCE,0.05); // Sets the error tolerance parameter to <5% training(handle1); // Trains the support vector machine using the inputs/outputs passed insertRandomErrors(inputs,outputs,500); // Takes the original inputs/outputs generated and adds random errors to the data int handle2=initSVMachine(); // Initializes a new support vector machine and returns a handle setInputs(handle2,inputs,7); // Passes the inputs (with errors) to the support vector machine setOutputs(handle2,outputs); // Passes the outputs (with errors) to the support vector machine setParameter(handle2,OP_TOLERANCE,0.05); // Sets the error tolerance parameter to <5% training(handle2); // Trains the support vector machine using the inputs/outputs passed double t1=testSVM(handle1,N_TestPoints); // Tests the accuracy of the trained support vector machine and saves it to t1 double t2=testSVM(handle2,N_TestPoints); // Tests the accuracy of the trained support vector machine and saves it to t2 Print("The SVM accuracy is ",NormalizeDouble(t1,2),"% (using training inputs/outputs without errors)"); Print("The SVM accuracy is ",NormalizeDouble(t2,2),"% (using training inputs/outputs with errors)"); deinitSVMachine(); // Cleans up all of the memory used in generating the SVM to avoid memory leak }
当脚本运行时,将在EA日志中生成以下结果。在具有5000个训练点的训练数据集中,我们可以引入500个随机误差。将该SVM与原始SVM的性能进行比较,该SVM的性能仅下降了1%。这是因为在训练过程中,支持向量机可以忽略数据集中的离群点,并且能够生成具有精确真实数据的令人惊讶的模型。这意味着SVM有可能成为一个更有用的工具,在提取复杂的模式和发现复杂的模式从嘈杂的数据集。

图5。由“SnICK”脚本生成的EA日志在Meta AtRADER 5中运行。
演示版
上述代码的完整版本可以从代码库下载,但是如果您从App Store购买支持向量机学习工具的完整版本,该脚本只能在您的终端上运行。如果只下载此工具的演示版本,则只能通过策略测试程序使用它。为了在工具的演示版本中测试“Schnick”代码,我将脚本重写为可由策略测试程序配置的“EA事务”。可以使用以下链接下载代码的两个版本:
- 完整版-使用配置在MetaTrader 5终端脚本(需要购买“支持向量机的学习工具”版)
- 演示版-在MetaTrader 5政策的测试程序配置使用EA交易(演示版的支持向量机的学习工具只需要)
支持向量机如何应用于应用市场?
应该承认,上面讨论的Schnick示例非常简单;然而,这个示例与支持向量机用于技术市场分析的用途有很多共同之处。
技术分析基本上利用历史市场数据预测未来价格走势。这和斯尼克的例子是一样的。我们使用前人的研究结果来确定一种新动物是否是Snink。此外,市场充满了噪声、误差和统计异常值,这使得支持向量机的应用成为一个有趣的概念。
大量技术分析交易方法的基础包括以下步骤:
- 监测几个指标
- 找出每个指标与潜在成功交易相关的条件。
- 观察每个指标并评估所有(或大多数)何时产生交易信号。
这种相似性使得有可能使用支持向量机通过相似的方法来产生新的交易信号。支持向量机学习工具的发展理念在于此。使用该工具的详细说明可以从应用程序商店下载。使用工具的过程如下:

图6。该框图显示了支持向量机工具在EA事务中的实现。
在开始使用“支持向量机学习工具”之前,了解如何生成训练输入和输出是很重要的。
如何生成培训输入?
以这种方式,您要用作输入的度量的初始化已经完成,就像您的新支持向量机一样。下一步是将索引句柄传递给新的支持向量机,并给出如何生成培训数据的说明。这是通过调用StEngistAsCalor()函数来完成的。此函数允许您将初始化索引句柄传递给支持向量机。这是通过传递包含句柄的整数数组来完成的。偏移和数据点的数量是这个函数的另外两个输入。
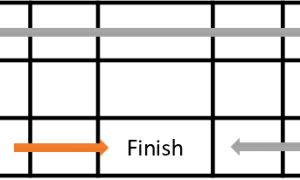
偏移值表示当前列和起始列之间的偏移以生成训练输入,而训练数据点的数目(以N表示)设置训练数据的大小。下面的图表说明了如何使用这些值。如果偏移值为4,N值为6,则支持向量机只使用白盒中捕获的列来生成训练输入和输出。类似地,如果偏移值为8并且N值为8,则支持向量机被告知仅使用在蓝色框中捕获的列来生成训练输入和输出。
一旦调用StEngistAsCurror()函数,就有可能调用GeNePosits()函数。此函数使用传递的索引句柄来生成要训练的输入数据集。

图7。显示用于偏移值和N值的烛台。
是如何产生训练输出的?
训练输出是通过基于历史价格数据模拟假设交易并确定交易是否成功而产生的。由于这个原因,还有几个参数用于指导支持向量机学习工具来评估假设事务的成功或失败。
第一个变量是OpthTrand。它的价值可以买(买)或卖(卖),并将对应于一个假设的买卖交易。如果这个值是BUY,那么在生成输出时,它将只关注假设购买交易成功的可能性。或者,如果价值被出售,它只会关注在产生输出时假设销售的可能性。
对于这些假设性交易,使用的下一个值是止损和获利。这些值由每个假设事务的点和设置停止和限制位来计算。
最后一个参数是事务的持续时间。这个变量是按小时计算的,以确保在最大时间内完成的事务被认为是成功的。添加这个变量的原因是为了避免支持向量机(SVM)在缓慢移动的水平市场中生成交易信号。
选择输入时的
考虑
在您的事务中实现支持向量机时,将一些想法添加到输入选择中是很重要的。类似于Schnick的例子,选择一个预期具有相似速率的输入是很重要的。例如,您可能想使用移动平均线作为输入,但是由于长期平均线价格会随着时间而显著变化,所以孤立移动平均线可能不是最好的备用输入。这是因为今天的移动平均线和六个月前的移动平均线将没有显著的相似性。
假设我们要执行欧元兑美元交易,并使用具有移动平均输入的支持向量机来生成“购买”交易信号。例如,目前的价格是1.10,但当它是0.55个六个月前,它正在生成培训数据。当训练支持向量机时,它找到的模式只有在价格约为0.55时才能产生交易信号,因为它只知道这些数据。因此,在价格降至0.55之前,您的支持向量机将永远不会生成交易信号。
相反,更适合于支持向量机的输入可以是MACD或类似的动量指示器,因为MACD的值独立于平均价格水平并且仅相对于移动生成的信号。我建议你试一试,看看如何得到最好的结果。
在选择输入时,我们还应考虑确保支持向量机具有足够数量的指标快照,以产生新的交易信号。根据您的交易经验,您会发现MACD只有在您过去有五列要查看时才有用(因为它显示趋势)。除非你能解释它是上升还是下降,单柱MACD可能是没有用的。因此,有必要将过去的MACD索引列传递到支持向量机。有两种方法可以做到这一点:
- 你可以创建一个新的自定义指标,用MACD指标过去五列计算趋势作为一个单一的价值。之后,自定义索引可以作为单个输入传递给支持向量机,或者
- 您可以使用支持向量机中的MACD索引的过去5列作为5个独立的输入。该方法是初始化MACD索引的5个不同实例。每个索引可用于初始化当前列的不同偏移量。之后,可以将不同索引的5个句柄传递给支持向量机。应该注意的是,第二个选项很容易导致EA事务执行时间的延长。输入越多,成功训练所需的时间就越长。
支持向量机在
EA交易中的实现
我准备了一个EA事务示例,展示了如何在个人事务中使用支持向量机(示例的副本可以从下面的链接下载,网址是https://www.mql5.com/zh/code/1229)。我希望这个EA交易可以给你很多支持向量机的经验。我建议你复制/修改/修改这个EA交易,以适应你自己的交易风格。这个EA的工作原理如下:
- 使用SaveCuttoOL库创建两个新的支持向量机。一组用于生成新的“买入”交易信号,另一组用于生成新的“卖出”交易信号。
- 七标准度量的初始化,及各指标的处理存储在一个整型数组(注:上述指标的任何组合可以作为输入,但需要通过一个单一的整数数组的形式来支持向量机)。
- 索引句柄数组传递给新的支持向量机。
- 使用索引处理阵列和其他参数,历史价格数据是用来产生精确的输入和训练支持向量机的输出。
- 一旦所有输入和输出完成,两个支持向量机也被训练。
- 训练支持向量机在埃阿被用来产生新的“买入”和“卖出”交易信号。产生一个新的“买”或“卖”的交易信号后,贸易将入库与手动停止损失和盈利的订单。
支持向量机的初始化和训练是在OnIIT()函数中进行的。下面给出了SaveTeaEA(注释)部分供您参考。
#property copyright "Copyright 2011, MetaQuotes Software Corp." #property link "https://www.mql5.com" #property version "1.00" #property indicator_buffers 7 //+---------Support Vector Machine Learning Tool Functions-----------+ //| The following #import statement imports all of the support vector //| machine learning tool functions into the EA for use. Please note, if //| you do not import the functions here, the compiler will not let you //| use any of the functions //+------------------------------------------------------------------+ #import "svMachineTool.ex5" enum ENUM_TRADE {BUY,SELL}; enum ENUM_OPTION {OP_MEMORY,OP_MAXCYCLES,OP_TOLERANCE}; int initSVMachine(void); void setIndicatorHandles(int handle,int &indicatorHandles[],int offset,int N); void setParameter(int handle,ENUM_OPTION option,double value); bool genOutputs(int handle,ENUM_TRADE trade,int StopLoss,int TakeProfit,double duration); bool genInputs(int handle); bool setInputs(int handle,double &Inputs[],int nInputs); bool setOutputs(int handle,bool &Outputs[]); bool training(int handle); bool classify(int handle); bool classify(int handle,int offset); bool classify(int handle,double &iput[]); void deinitSVMachine(void); #import #include <Trade/Trade.mqh> #include <Trade/PositionInfo.mqh> #include <Trade/HistoryOrderInfo.mqh> //+-----------------------Input Variables----------------------------+ input int takeProfit=100; // TakeProfit level measured in pips input int stopLoss=150; // StopLoss level measured in pips input double hours=6; // The maximum hypothetical trade duration for calculating training outputs. input double risk_exp=5; // Maximum simultaneous order exposure to the market input double Tolerance_Value=0.1; // Error Tolerance value for training the SVM (default is 10%) input int N_DataPoints=100; // The number of training points to generate and use. //+---------------------Indicator Variables--------------------------+ //| Only the default indicator variables have been used here. I //| recommend you play with these values to see if you get any //| better performance with your EA. //+------------------------------------------------------------------+ int bears_period=13; int bulls_period=13; int ATR_period=13; int mom_period=13; int MACD_fast_period=12; int MACD_slow_period=26; int MACD_signal_period=9; int Stoch_Kperiod=5; int Stoch_Dperiod=3; int Stoch_slowing=3; int Force_period=13; //+------------------Expert Advisor Variables------------------------+ int tickets[]; bool Opn_B,Opn_S; datetime New_Time; int handleB,handleS; double Vol=1; //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ int OnInit() { New_Time=0; int handles[];ArrayResize(handles,7); //+------------------------------------------------------------------+ //| The following statements are used to initialize the indicators to be used for the support //| vector machine. The handles returned are stored to an int[] array. I have used standard //| indicators in this case however, you can also you custom indicators if desired //+------------------------------------------------------------------+ handles[0]=iBearsPower(Symbol(),0,bears_period); handles[1]=iBullsPower(Symbol(),0,bulls_period); handles[2]=iATR(Symbol(),0,ATR_period); handles[3]=iMomentum(Symbol(),0,mom_period,PRICE_TYPICAL); handles[4]=iMACD(Symbol(),0,MACD_fast_period,MACD_slow_period,MACD_signal_period,PRICE_TYPICAL); handles[5]=iStochastic(Symbol(),0,Stoch_Kperiod,Stoch_Dperiod,Stoch_slowing,MODE_SMA,STO_LOWHIGH); handles[6]=iForce(Symbol(),0,Force_period,MODE_SMA,VOLUME_TICK); //----------Initialize, Setup and Training of the Buy-Signal support vector machine---------- handleB=initSVMachine(); // Initializes a new SVM and stores the handle to 'handleB' setIndicatorHandles(handleB,handles,0,N_DataPoints); // Passes the initialized indicators to the SVM with the desired offset // and number of data points setParameter(handleB,OP_TOLERANCE,Tolerance_Value); // Sets the maximum error tolerance for SVM training genInputs(handleB); // Generates inputs using the initialized indicators genOutputs(handleB,BUY,stopLoss,takeProfit,hours); // Generates the outputs based on the desired parameters for taking hypothetical trades //----------Initialize, Setup and Training of the Sell-Signal support vector machine---------- handleS=initSVMachine(); // Initializes a new SVM and stores the handle to 'handleS' setIndicatorHandles(handleS,handles,0,N_DataPoints); // Passes the initialized indicators to the SVM with the desired offset // and number of data points setParameter(handleS,OP_TOLERANCE,Tolerance_Value); // Sets the maximum error tolerance for SVM training genInputs(handleS); // Generates inputs using the initialized indicators genOutputs(handleS,SELL,stopLoss,takeProfit,hours); // Generates the outputs based on the desired parameters for taking hypothetical trades //---------- training(handleB); // Executes training on the Buy-Signal support vector machine training(handleS); // Executes training on the Sell-Signal support vector machine return(0); }
高级支持向量机事务
在支持向量机学习工具中为更多的高级用户构建了更多的功能。这个工具允许用户传送他们自己的自定义输入和输出数据(例如Snink示例)。这样,你可以定制自己的输入和输出标准支持向量机,手动通过在训练数据集。这为使用支持向量机的事务的每一个方面创造了机会。
它不仅可以利用支持向量机产生新的交易信号,也可以用来产生交易、基金管理、新的先进指标和其他信号。但是,为了确保没有错误,理解这些输入和输出是如何构造的是很重要的。
输入:作为一维双精度值数组的输入被传递给支持向量机。请注意,您创建的任何输入都必须导入为双精度值。布尔,整数和其他类型的值必须被转换为双精度值才可以转移到支持向量机。输入具有以下格式要求。示例:假设我们希望输入具有3个输入x和5个训练点的输入。由于这个原因,我们的双精度阵列必须是15位长格式:
A1、B1、C1、A2、B2、C2、A3、A3、B3、C3、A4、A4、B4和A4。
导入一个输入量值也是必要的。在这种情况下,nl输入=3。
输出:输出作为布尔数组传递。这些布尔值对于支持向量机相对于每个组的输入输入的输出是必需的。根据上面的例子,有5个训练点。在这种情况下,我们将导入一个5单位布尔输出值数组。
一般描述:
- 当生成输入和输出时,确保数组的长度与输入值匹配。如果不匹配,将产生一个错误来提醒您一个偏差。示例:如果我们传入了N_Input=3,并且输入是16长度的数组,则会发生错误(因为N_input是3,这意味着任何输入数组的长度必须是3的倍数)。此外,确保输入集的数量等于输出的输出数量。类似地,如果N_Input=3,输入长度为15,输出长度为6,则会出现另一个错误(因为您有五组输入和六组输出)。
- 尝试确保输出中有足够的变量。示例:如果传入100个训练点(表示输出数组的长度为100),并且所有值都是true(其他值都是false),那么true和false之间的差别是不够的。这导致了SVM的快速训练,但结果非常差。训练集越多样化,支持向量机就越有效。
Meta QuasoTM软件公司HTTPS://www. MQL5.COM/En/TousLe/588.从英文翻译成原始
文章
MyFxtop迈投(www.myfxtop.com)-靠谱的外汇跟单社区,免费跟随高手做交易!
免责声明:本文系转载自网络,如有侵犯,请联系我们立即删除,另:本文仅代表作者个人观点,与迈投财经无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。