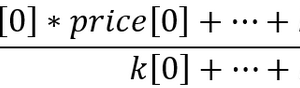介绍
所有交易员都愿意通过建立自己的交易系统,尽快成长为分析师。多年来,他们一直试图找到市场趋势,测试交易理念。每个想法都可以用不同的方式进行测试——从搜索战略测试者优化模型的最佳参数到科学(有时是伪科学)市场研究。
本文提出研究统计假设,一种研究和推理验证的统计分析工具。让我们使用Statistica开发工具包来测试不同的假设,以及使用迁移的数值分析库alglib mql5的示例。
1。假设的概念
“统计假设”的概念有几个定义。其中一些假设涉及正在讨论的对象或现象的统计特征。
统计假设是关于概率规律和问题现象的假设。
其他定义指出,统计特性必须与一些随机变量的分布或这些分布的参数有关。
统计假设是关于统计分布参数或随机变量分布原理的假设。
在数理统计文献中,“假设”的概念被解释为第二种方式。然后我们可以区分:
- 参数假设(关于分布参数值或两个分布参数比较的假设);
- 非参数假设(关于随机值分布类型的假设)。
在下一章中,我们将讨论一种测试假设的方法。
2。测试假设。理论
被检验的假设称为零假设(0)。竞争假设(1)是其替代方案。它翻转了零硬币,也就是说,逻辑上它拒绝了零假设。
想象一下一些交易系统的一组止损数据社区。我们将解释测试两个假设的基础。
0-平均停车损失等于30分。
1-平均停损值不等于30分。
接受和拒绝假设的变化:
- 0为真且被接受;
- 0错误,拒绝同意1;
- 0为真,但拒绝同意1;
- 零是错误的,但被接受了。
最后两个变量与错误有关。
现在已指定显著性级别值。这是一个可接受的替代假设,而真正的假设是零假设的概率(第三个变量)。这种概率是首选的最小化。
在我们的例子中,如果我们假设停止损失平均不等于30点,即使它实际上是时间,这样的错误也会发生。
通常显著性水平值(a)等于0.05。这意味着不超过5%的零假设检验统计数据可以进入临界区。
在我们的例子中,测试统计数据将在经典图表(图例)上进行评估。1)。

传说。1。按正态概率规律分布的检验统计量
如果接受零假设,则检验统计数据不应达到红色区域。例如,假设测试统计数据是正态分布。
每个测试都有自己的计算测试统计数据的公式。
变量4表示第二个类型(beta)有错误。在我们的例子中,如果假设停止损失等于平均30点,但实际上不等于该点,就会发生这样的错误。
三。统计假设检验示例
示例的源数据存储在数据中。XLS文件。
3.1。依赖样本测试
想象一下下面的场景。假设一个交易系统生成一个交易社区。让我们从盈利交易中抽取100个交易量单位的样本。源数据以利润形式提供。
剔除异常值后,利润样本的描述性统计见表1:
。

表1。利润样本统计
样本柱状图如下所示(图例。2)。

传说。2。利润样本直方图
平均83.4分,中位数83分。
如果入口点改变了几个点会发生什么?例如,提高门票价格的门票可以在出现交易信号后放置。
它将如何影响结果?这个问题可以用统计假设来回答。
在统计发展工具包中,我们正式检查了样本是否来自一般社区:
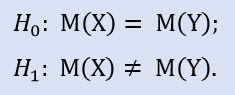
如果我们把进入点改为15点,我们将收到一份新的利润样本。理想结果应该如下(图例。3)。

传说。三。利润表和新的利润样本
由于样本中位数的差异,接受替代假设的概率很高。
然而,这张照片很难得到,因为市场上没有更好的价格。在我的例子中,第二个样本包括了入院价格改变后的84笔交易。其他15项交易根本没有执行。这个修改过的样本将被命名为“新利润实实在在”。
在“胡须盒”型图形中,两个样本之间没有显著差异。

传说。4。利润与新利润实样图
让我们用相关的样本做一个非参数Wilcoxon标记水平测试。
结果见表2:

表2。Wilcoxon收益和新利润真实样本测试结果
显著性水平值很高,有利于零假设。
这样,我们可以说更改入口点不会影响系统的生产力。相对来说。从绝对值来看,该系统错过了进入点,导致利润下降。
Wilcoxon测试可以用mql5程序完成。尽管与指定m值的分布中位数相比,这一差异并不显著。
我们继续研究:
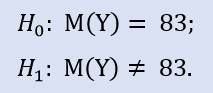
alglib库包含以下进程:calglib::wilcoxon signedranktest()。它给出了三种测试的结果:双边测试、左测试和右测试。
脚本test_profits.mq5提供了一个计算例程。日志“专家”对新利润实际样本有以下结果:
OO 0 12:04:08.814 test_profits (EURUSD.e,H1) p-value for the two-sided test: 0.7472 HD 0 12:04:08.814 test_profits (EURUSD.e,H1) p-value for the left-sided test: 0.6285 CM 0 12:04:08.814 test_profits (EURUSD.e,H1) p-value for the right-sided test: 0.3736
左侧测试的形式:
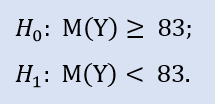
在这里,我们检查备选方案,因为新利润实际样本的中值可以大于或等于83。H 0的假拒绝概率为0.63。所以H0被接受。
正确的测试如下:
0
在测试中,我们检查了替代方案,即新利润实样本的中值可以小于或等于83。H 0的假拒绝概率为0.37。所以H0被接受。
3.2。测试独立样本
假设我们想检查不同的经纪人处理交易订单的速度,以及经纪人之间相关交易订单的执行时间是否存在差异。
因此,使用两个源数据样本进行分析。每个样本最初包含50个观察点。删除异常后,第一个样本(经纪公司)保留48个观察点,第二个样本(经纪公司B)保留49个观察点。可以在执行时间窗体中找到数据。
我们继续研究:
1
让我们在图片(图例)上显示一个示例索引。5)。从图中可以看出,中值是不同的,但并不显著。
2
图形图例。5。经纪公司A、B数据样本图
因为我们不知道每个样本的分布,所以我们将它与非参数检验进行比较。
例如,让我们实现mann-whitney U-test(表3)。它被认为是最有用的。
3
表3。曼惠特尼U型经纪公司A和B的数据样本测试结果
结论:实验结果不同,样本相等的零假设不符合1。
mann-whitney U-test可以用mql5程序完成。alglib库中有一个calglib::mann whitneyutest()进程。它给出了三种测试的结果:双边测试、左测试和右测试。
脚本test_time_execution.mq5提供了一个计算例程。以下结果可用于“专家”日志中的样本比较:
MR 0 12:55:08.577 test_time_execution (EURUSD.e,H1) p-value for the two sided test: 0.0001 QF 0 12:55:08.577 test_time_execution (EURUSD.e,H1) p-value for the left-sided test: 1.0000 PF 0 12:55:08.577 test_time_execution (EURUSD.e,H1) p-value for the right-sided test: 0.0001
左侧测试的形式:
4
零假设是A经纪公司的数据样本可以大于或等于B经纪公司的数据样本,另一种假设是拒绝接受。H 0的错误拒绝概率为1.0。所以H0被接受。
正确的测试如下:
5
零假设是A经纪公司的数据样本可以小于或等于B经纪公司的数据样本,另一种假设是拒绝接受。
H 0的错误拒绝概率为0.0。所以h0拒绝同意1。
3.3。相关性测试
想象一下战略组合。目标是减少投资组合中的策略数量。
选择的标准如下:如果两个策略的比较平均停止,其中一个策略将从组合中删除。让我们取两个不同的系统作为两个例子。假设:系统有相同的入口响应,但不同的出口响应。
我们将使用斯皮尔曼的水平顺序相关测试。以下是数据文件“相关”形式中的三个示例。
检查相关系数是否等于零:
6
比较stops1-stops2样本对得出以下结果(表4)。
7
表4。停止1和停止2样本的Sparman等级序列相关试验
在这种情况下,关于样本元素之间缺乏相关性的零假设不能被排除在替代方案之外。所以它被接受了。
图例中的数字。6表明数据不能形成任何明显的配置。相反,数据分散在整个计划中。
8
图形图例。6。采场1和采场2样品分散图
Stops1-Stops3样本之间关系测试结果如表5所示:
9
表5。Stops 1和Stops 3样本的Sparman等级序列相关测试结果
在这种情况下,零假设被拒绝,因为错误概率太低。
因此,接受现有关系的替代方案。关系如下所示(图例。7)。
0
图形图例。7。Stops1和Stops3样品的分散图
用于确认结果的MQL5代码。test_correlation.mq5包含一个计算例程。
alglib库包括进程calglib::spearman秩相关显著性(),实现了spearman秩相关系数显著性测试。
日志包括以下记录:
OO 0 12:57:43.545 test_correlation (EURUSD.e,H1) ---===Samples Stops1 and Stops2===--- GO 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the two-sided test: 0.9840 KK 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the left-sided test: 0.4920 JJ 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the right-sided test: 0.5080 DM 0 12:57:43.545 test_correlation (EURUSD.e,H1) HJ 0 12:57:43.545 test_correlation (EURUSD.e,H1) ---===Samples Stops1 and Stops3===--- NS 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the two-sided test: 0.0002 RO 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the left-sided test: 0.9999 FG 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the right-sided test: 0.0001
左侧测试表:
1
在本试验中,验证了变量之间存在非负相关(即相关系数为零或负)的零假设。
左检验表明,stops1-stops2样本对的零假设是可以接受的。左检验表明,stops1-stops3样本对的零假设也被接受。一个合乎逻辑的问题是,“为什么stops1-stops2样本之间和stops1-stops3样本之间没有联系?”原因是检验结果大于等于零。在第一种情况下,“等于零”对于h0非常重要,在第二种情况下,“大于零”。
正确的测试如下:
2
这里,是否检验了负相关的零假设?
对于stops1-stops2的样本对,右侧测试表明零假设被接受。对于stops1-stops3测试的右侧,否定了零假设。
最后一条评论。试验表明,1号站和3号站之间存在正相关概率。这种相关性的强度是平均值。因此,由交易员决定是否拒绝策略1或3。
结论
本文试图用实例说明定量变量可以用数理统计的方法来评价。我希望新开发人员会发现这篇文章对他们未来的交易系统非常有用。我也希望关于使用数理统计的系列文章能够继续下去。
库文件alglib需要单独下载。
本文由MetaQuotes Software Corp.翻译自俄语原文
,网址为https://www.mql5.com/ru/articles/1240。
MyFxtop迈投(www.myfxtop.com)-靠谱的外汇跟单社区,免费跟随高手做交易!
免责声明:本文系转载自网络,如有侵犯,请联系我们立即删除,另:本文仅代表作者个人观点,与迈投财经无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。